2019年10月6日
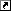
RISC-Vのバイナリダンプを逆アセンブルする
目次: RISC-V
相変わらず空き時間にRISC-Vのエミュレータを書いています。RV64IMACくらいが必要なのですが、意外と命令の種類が多くていっぺんにやるのは面倒なので、HiFive Unleashedのファームウェアを動かしてみて、足りない命令から実装していくスタイルで開発しています。
HiFive Unleashedの電源を入れたときに真っ先に起動してくるファームウェアというかブートローダはZSBL(Zeroth Stage Boot Loader), FSBL(First Stage Boot Loader)という名前です。
なんと親切なことにソースコードが公開されています(GitHub - Freedom U540-C000 Bootloader Codeのリンク)。素晴らしいですね……。
なぜかUnleashedから引っこ抜いてきたバイナリと、手元でコンパイルしたZSBL, FSBLのバイナリが一致しません。何か間違っているのかも?ちょっと気になります。しかしながら、ソースコードが公開されている意義は非常に大きいです。
メモリマップも公開されています。SiFive Freedom U540 SoCのサイトからダウンロードできます。
Unleashedリセット〜ZSBLを例に解説
U540のマニュアルによると、リセット直後のPCは0x1004で、その後はMSELの値を見て、適切な場所に飛ぶとあります。MSELというのは、Unleashedボード上のDIPスイッチのことです。購入後、変えていなければ状態だと全部ON、つまり0xfになっていると思います。
リセット直後に実行される領域の周辺バイナリをダンプしてみましょう。ダンプには拙作のmemaccess(GitHubへのリンク)を使っています。
Unleashed 0x1000〜0x1040領域のダンプ
# ma db 0x1000 0x40 00001000 0f 00 00 00 97 02 00 00 03 a3 c2 ff 13 13 33 00 00001010 b3 82 62 00 83 a2 c2 0f 67 80 02 00 00 00 00 00 00001020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00001030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00001040
何かが書いてあるようですが、RISC-Vのバイナリがスラスラ読めるほど達人ではないので、ファイルにダンプして逆アセンブルします。
Unleashed 0x1000〜0x1040領域の逆アセンブル
$ riscv64-unknown-elf-objdump -EL -D -b binary -m riscv:rv64 --adjust-vma=0x1000 reset.bin
reset.bin: file format binary
Disassembly of section .data:
0000000000001000 <.data>:
1000: 0000000f fence unknown,unknown
1004: 00000297 auipc t0,0x0
1008: ffc2a303 lw t1,-4(t0) # 0x1000
100c: 00331313 slli t1,t1,0x3
1010: 006282b3 add t0,t0,t1
1014: 0fc2a283 lw t0,252(t0)
1018: 00028067 jr t0
...
先頭が変な命令に見えますが、これは命令ではなくMSELです。値は先程も言ったとおり0xfです。実行されるのは0x1004からです。大した量でもないし、1行毎に見ていきます。
- 0x1004: auipc t0, 0x0
- PC + 0をt0にロードします。t0: 0x1004です。
- 0x1008: lw t1,-4(t0) # 0x1000
- レジスタt1にアドレスt0 - 4 = 0x1004 - 4 = 0x1000つまりMSELをロードします。t1: 0xfです。
- 0x100c: slli t1,t1,0x3
- レジスタt1を3ビット左シフト(= 8倍)します。t1: 0xf << 3 = 0x78です。
- 0x1010: add t0,t0,t1
- レジスタt0とt1を足します。t0: です。t0: 0x1004 + 0x78 = 0x107cです。
- 0x1014: lw t0,252(t0)
- レジスタt0にt0 + 252のアドレスからロードします。アドレスは0x107c + 252 = 0x1178です。後述のとおりt0: 0x10000です。
- 1018: jr t0
- レジスタt0のアドレスにジャンプします。すなわち0x10000にジャンプします。
参考として、アドレス0x1178に何が書いてあるか示しておきます。付近の領域0x1100〜0x1180にはMSELの値に応じたジャンプ先のアドレスが書いてあります。MSELが他の値になったらどこにジャンプするか、眺めてみると面白いかと思います。
Unleashed 0x1000〜0x1040領域のダンプ
# ma dd 0x1100 0x80 00001100 00001004 00000000 20000000 00000000 00001110 30000000 00000000 40000000 00000000 00001120 60000000 00000000 00010000 00000000 00001130 00010000 00000000 00010000 00000000 00001140 00010000 00000000 00010000 00000000 00001150 00010000 00000000 00010000 00000000 00001160 00010000 00000000 00010000 00000000 00001170 00010000 00000000 00010000 00000000 ★0x1178には0x10000が書いてある 00001180
マニュアルの言うとおり、MSELが0xfの場合、リセット後ZSBLにジャンプ、アドレスで言うと0x10000にジャンプすることが確認できました。
以降も同様に0x10000付近をダンプし、逆アセンブルしたり、エミュレータに実行させてみたりして、開発を進めています。今はZSBLは通過して、FSBLの先頭の方まで実行できるようになりました。いうなれば、砂山にトンネルを掘っているような気分でしょうか、なかなか面白いです。
通常は逆アセンブルだけだと処理の意図を掴むことが難しいですけども、その点U540はソースコードが読めるため、当たりを付けることが比較的容易です。しばらくは素敵なおもちゃになりそうなボードです。
コメント一覧
- コメントはありません。
 この記事にコメントする
この記事にコメントする
2019年10月12日
台風19号
あの台風15号(Faxai)(2019年9月8日の日記参照)を超える、かつてない規模の台風19号(Hagibis)が来るということで、窓にガラス飛散防止でダンボールを貼ってみたり、食料、水を買い込んで備えていました。
都内だと多摩川沿いの一部堤防のない地域が水浸し、東日本だと長野、宮城が洪水で大変なことになっているそうで、東京の治水事業には感謝しかありません。
我が家からはやや遠いですが、最寄りの大きな川といえば多摩川です。水位が大変なことになっていて、思わずスクリーンショットを撮ってしまいました……。
家
我が家は北と東に窓がありまして、台風15号のときは北からガンガン風と雨が吹き付けていたため、あまりの風圧に、雨が窓サッシの隙間から侵入していました。壁に飛来物が当たり、ものすごい音もしていました(窓の真横に当たり、窓にはギリギリ当たらず本当に幸運だった)。今回はどうやら西、ないし、南から吹き付けていたようで、15号のときほど被害はありませんでした。
今回は全体的に幸運でしたが、災害への備えは日頃からやっておいて損はないですね。
家財
家の外にある家財は車くらいしかないので、台風が過ぎた後に見に行ってみましたが、特に飛来物が当たった形跡もなく、何ともなかったです。良かった良かった。
コメント一覧
- コメントはありません。
この記事にコメントする
2019年10月13日
Gitの小技、コミットID取得
目次: Linux
最近、会社でCI/CDで自動化のマネごとを始めました。といっても大したことはなくて、ビルドしてDebianやRPMパッケージを作って、Webサーバーにぶっこむだけです。
Nightlyビルドのパッケージを作成する際に、パッケージ名の最後にGitのコミットIDを付加しようと思ったのですが、方法が分かりません。調べてみるとrev-parseというコマンドを使うそうです。知らなかった。
GitのコミットID(全体、短縮)を取得する
$ git rev-parse HEAD 5ab7d0ae0c170fc0409d564fe945aac5ce54f86c $ git rev-parse --short HEAD 5ab7d0ae0c1
ID全部だと長すぎるため --shortオプションを使うとより良いです。
コメント一覧
- コメントはありません。
この記事にコメントする
2019年10月14日
linux-nextでdirtyがバージョン情報に付く仕組み
目次: Linux
Linuxというかlinux-nextですが、リポジトリ内のファイルをオリジナルから変更してビルドした場合、バージョン情報の最後に -dirtyが付きます。あれはどうやっているのだろう??と気になりました。
Makefileを眺めていると、scripts/setlocalversionというスクリプトでローカルバージョンを付与しているように見えます。
試しにcleanなリポジトリでscripts/setlocalversionを実行すると、-next-20191009のようなlocalversionのみ(※)が表示され、ファイルを適当に書き換えてから実行すると、-next-20191009-dirtyになりました。このスクリプトで当たりっぽいです。
もしLinux Upstreamカーネルで試す場合は、CONFIG_LOCALVERSION_AUTOをyにして、make prepareを実行する必要があります。そうしないとscripts/setlocalversionを実行しても "+" しか表示されません。
(※)この文字列はトップディレクトリのlocalversion-nextというファイルに書いてあります。
Gitの小技、リポジトリ変更を検知
スクリプトsetlocalversionを追いかけてみるとgit --no-optional-locks status -uno --porcelainで変更を検知して、-dirtyを出力するかどうか決めていました。オプション --porcelainのヘルプを見ると「スクリプトなどで処理しやすい形式でstatusを出力する」とのことです。へえー、こんなのあるんだ。初めて知りました。
オプション --no-optional-locksはロックを取らずに実行するという意味です。ヘルプ曰く、バックグラウンドでstatusを実行する際に、他のgit statusプロセスと衝突するので、指定した方が良いとのこと。手動で使うことはなさそうだし、気にしなくて良いでしょう。
オプション-unoは --untracked-files=noの省略形です。効果は実際に見た方が早いです。以下をご覧ください。
Gitリポジトリに変更を加える
#### scripts/setlocalversionを書き換え $ vim scripts/setlocalversion #### 未追跡ファイルaaaを作成 $ touch aaa
上記の変更を加えたうえで、オプション -unoなし、オプション -unoありで、それぞれ実行してみます。
Gitリポジトリに変更が生じているか取得する(-unoなし、あり)
$ git status --porcelain M scripts/setlocalversion ?? aaa $ git status -uno --porcelain 下記と同じ $ git status --untracked-files=no --porcelain M scripts/setlocalversion
見た目で明らかだとは思いますが、オプション -unoが指定されていない場合は、未追跡のファイルaaaも表示されますが、-unoを指定すると未追跡のファイルは無視します。
スクリプト内でGitリポジトリが変更されたか?されていないか?を判定する必要は、普通の人はほぼ無いと思うんですけど……、もし必要が生じたら、sedとかgrepとかでゴチャゴチャやらずに、オプション --porcelainを使いましょう。
コメント一覧
- コメントはありません。
この記事にコメントする
2019年10月20日
イコライザー
普段ヘッドフォンを使っているのですが、若干、低音が足りないなと思うことがあります。
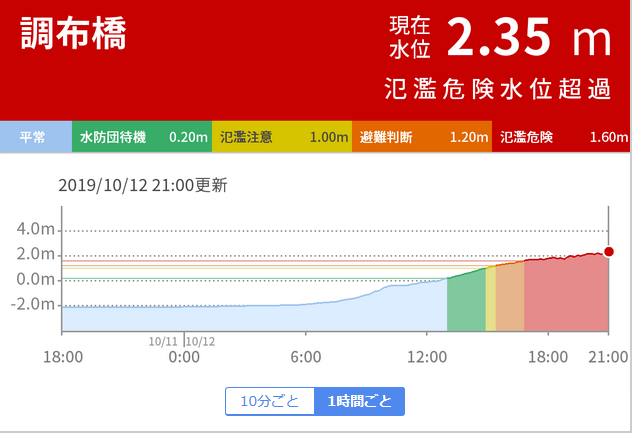
Windows標準のBass Boostは設定項目が2つと大変シンプルでわかりやすいですが、音の歪みを防止するためなのか、Boostを有効にすると音が全体的に小さくなってしまうのが辛いところです。
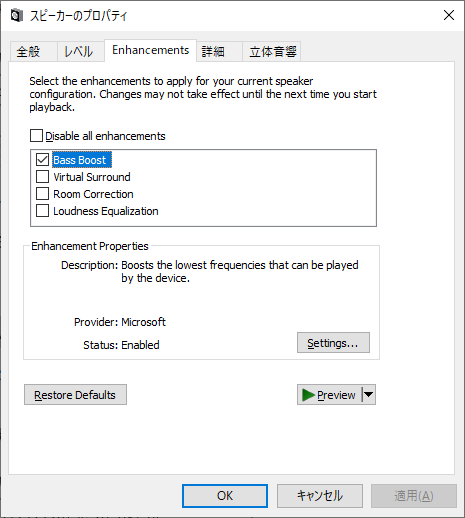
最大値は24dBですが、最大値に設定しようものなら非常に音が小さくなります。良いヘッドフォンアンプを持っていればアンプ側で音量を上げれば良いですが、PCのヘッドフォン端子に直接ヘッドフォンを接続している場合は、ボリュームを最大にしても聞こえなくなる可能性があります。
これはイマイチだなあってことで、代わりを探していましたら、VLC Playerのイコライザはシンプルデザインかつ設定の幅が広くて、とても良かったです。
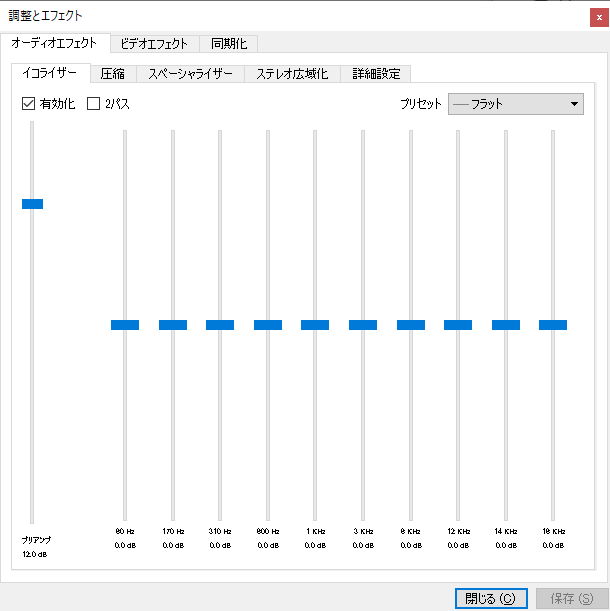
全体の音量(Preamp)と、各帯域ごとの音量を別々に調整できるので、WindowsのBass Boostに似た設定もできる(Preampを下げ、80Hz帯を上げる)し、音が歪むのもお構いなしの設定にもできます。あまりやりすぎるとバリバリ言い始めるのでほどほどに、ですけど。
コメント一覧
- コメントはありません。
この記事にコメントする
2019年10月21日
線形探索と2分探索の話
Twitterで線形探索と2分探索の性能逆転ポイントはどこか?という話をしていて、気になったので測ってみました。
線形探索と2分探索は、要素数をNとしたとき、処理量オーダーでいうとO(N) とO(logN) となり、圧倒的に2分探索が速いです。ただし処理量オーダーによる比較は、Nが十分に大きい場合に成り立ちます。Nが極端に小さい場合は線形探索が2分探索と同等、もしくは、勝ってしまう領域があるのではないか?という話です。
結論だけ先に言えば2分探索の圧勝でした。かなりNを小さく(100程度)しないと、線形探索に勝ち目はなかったです。個人的にはN=1000〜2000程度ならば線形探索が勝つ予想をしていましたが、全くそんなことはなかったです。2分探索スゴい。
探索速度検証
検証方法ですが、線形探索(lsearch)を実装して、Cライブラリ(GNU libc 2.29)に実装されている2分探索(bsearch)と速度を比較しました。線形探索lsearchのAPIは2分探索と揃えています。
処理の概要は下記の通りです。探索の対象は同じものを使っています。
- 要素数Nの配列を作る
- 配列を乱数で埋める
- 配列をソートする(bsearchはソート済みの配列にしか使えない)
- 2分探索(bsearch)をM回実行する、時間を測る
- 線形探索(lsearch)をM回実行する、時間を測る
ソースコードは下記のとおりです。
線形探索と2分探索の速度比較プログラム
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <sys/time.h>
int comp(const void *key, const void *val)
{
int k = *(int *)key;
int v = *(int *)val;
return k - v;
}
void *lsearch(const void *key, const void *base,
size_t nmemb, size_t size,
int (*compar)(const void *, const void *))
{
void *v = (void *)base;
size_t i;
for (i = 0; i < nmemb; i++) {
if (compar(key, v) == 0)
return v;
v += size;
}
return NULL;
}
int main(int argc, char *argv[])
{
int *array, *keys;
int **fb, **fl;
size_t n, kn, i;
struct timeval start_b, end_b, ela_b;
struct timeval start_l, end_l, ela_l;
if (argc < 3) {
fprintf(stderr, "usage:\n\t%s n loop\n", argv[0]);
return -1;
}
n = atoi(argv[1]);
kn = atoi(argv[2]);
if (n == 0 || kn == 0) {
fprintf(stderr, "usage:\n\t%s n loop\n", argv[0]);
return -1;
}
srand(time(NULL));
array = (int *)malloc(n * sizeof(int));
keys = (int *)malloc(kn * sizeof(int));
fb = (int **)malloc(kn * sizeof(int *));
fl = (int **)malloc(kn * sizeof(int *));
for (i = 0; i < n; i++) {
array[i] = rand() % (int)n;
}
for (i = 0; i < kn; i++) {
keys[i] = rand() % (int)n;
}
qsort(array, n, sizeof(int), comp);
gettimeofday(&start_b, NULL);
for (i = 0; i < kn; i++) {
fb[i] = bsearch(&keys[i], array, n, sizeof(int), comp);
}
gettimeofday(&end_b, NULL);
timersub(&end_b, &start_b, &ela_b);
gettimeofday(&start_l, NULL);
for (i = 0; i < kn; i++) {
fl[i] = lsearch(&keys[i], array, n, sizeof(int), comp);
}
gettimeofday(&end_l, NULL);
timersub(&end_l, &start_l, &ela_l);
for (i = 0; i < kn; i++) {
if (fb[i] && fl[i] && *fb[i] == *fl[i])
continue;
if (fb[i] != fl[i])
printf("diff %d: key:%d, fb:%d, fl:%d\n",
(int)i, keys[i],
(fb[i]) ? *fb[i] : -1,
(fl[i]) ? *fl[i] : -1);
}
printf("n:%d, loop:%d, bin: %d.%06d[s], lin: %d.%06d[s]\n",
(int)n, (int)kn,
(int)ela_b.tv_sec, (int)ela_b.tv_usec,
(int)ela_l.tv_sec, (int)ela_l.tv_usec);
return 0;
}
コピペしていたり、エラー処理が甘かったり、適当な書き方で申し訳ないですが、性能比較が目的なのでそこは見逃していただくとして。測ってみるとこんな結果になりました。
環境はRyzen 7 2700, Debian 10 (Linux 5.2.0-3-amd64) です。コンパイラはgcc 9.2.1で、最適化レベルは -O2 です。
線形探索と2分探索の速度比較(100万回)
$ for i in 1 `seq 25 25 500`; do ./a.out $i 1000000; done n:1, loop:1000000, bin: 0.001702[s], lin: 0.001710[s] n:25, loop:1000000, bin: 0.019114[s], lin: 0.011656[s] n:50, loop:1000000, bin: 0.022469[s], lin: 0.018549[s] n:75, loop:1000000, bin: 0.026413[s], lin: 0.023774[s] n:100, loop:1000000, bin: 0.028008[s], lin: 0.028900[s] n:125, loop:1000000, bin: 0.029601[s], lin: 0.034308[s] ★この辺りで逆転される★ n:150, loop:1000000, bin: 0.030671[s], lin: 0.040280[s] n:175, loop:1000000, bin: 0.031898[s], lin: 0.045664[s] n:200, loop:1000000, bin: 0.032771[s], lin: 0.048153[s] n:225, loop:1000000, bin: 0.033985[s], lin: 0.052148[s] n:250, loop:1000000, bin: 0.034322[s], lin: 0.055871[s] n:275, loop:1000000, bin: 0.034761[s], lin: 0.059935[s] n:300, loop:1000000, bin: 0.035766[s], lin: 0.065683[s] n:325, loop:1000000, bin: 0.036407[s], lin: 0.070435[s] n:350, loop:1000000, bin: 0.037010[s], lin: 0.072971[s] n:375, loop:1000000, bin: 0.036926[s], lin: 0.077805[s] n:400, loop:1000000, bin: 0.037422[s], lin: 0.082656[s] n:425, loop:1000000, bin: 0.037844[s], lin: 0.086240[s] n:450, loop:1000000, bin: 0.038894[s], lin: 0.089354[s] n:475, loop:1000000, bin: 0.038516[s], lin: 0.093286[s] n:500, loop:1000000, bin: 0.038590[s], lin: 0.100021[s]
結果の見方ですが、最初のn: は配列の要素数です。次のloop: は何回検索するかを表しています。bin: は2分探索bsearch、lin: は線形探索lsearchを表し、それぞれloop回実行し終わるまでの時間を出しています。
線形探索と2分探索の逆転ポイントは実行するたびに割とズレますが、N=500にもなれば、もはや線形探索に勝ち目はありません。2分探索強いです。
ループ回数を増やしても大勢に影響はありませんが、ループ回数を増やすほどlsearchがわずかに有利になるようです。N=1のときlsearchが勝つことが多いので、関数の呼び出しコストが低いのかも?
個人的に予想していたN=1000〜2000のレンジでは、線形探索は桁違いに遅かった(2分探索の10倍近く時間がかかる)です。私の予想は当てにならんなあ。
コメント一覧
- コメントはありません。
この記事にコメントする
2019年10月22日
天皇誕生日の移動
以前対応した(2018年10月12日の日記参照)カレンダーの設定が間違っていたので、修正しました。具体的には下記のとおりです。
- 2018年まで12/23: 祝日、おなじみ天皇誕生日
- 2019年12/23: 祝日ではない、天皇誕生日は2019年は存在しない
- 2020年から2/23: 祝日、新しい天皇誕生日
詳細は内閣府のサイトに掲載されています。特に2019年と2020年に関しては休日の一覧が載っていて、とてもわかりやすいです。
コメント一覧
- コメントはありません。
この記事にコメントする
2019年10月27日
ニッケル水素電池の使い道
目次: 電池
家にはニッケル水素電池がたくさん(15本くらい、※1)あって使い道がなくて困っていたのですが、停電時にモバイルバッテリーにすれば良いのでは?と思い立ち、OwltechのOWL-DBU1という製品(製品サイトへのリンク)を買いました。
乾電池4本で5V 1A出力が可能な製品です。最近のスマホはバッテリー容量が大きく、乾電池2本を使う製品ですと満足に充電できません。その点、この製品は乾電池が4本使えるのでGood です。
不満な点は専用ケーブル(硬い、短い)でないと充電開始しないことです。専用ケーブルをなくすとゴミと化します。
(※1)いきなり電池を15本買ったわけじゃなくて、買ったものもあるし、家電に付属していたものもあって、じわじわ増えて今の数です。
乾電池タイプのモバイルバッテリーとニッケル水素電池
乾電池を使うタイプのモバイルバッテリー製品は、アルカリ電池(1.5V)が前提で、ニッケル水素電池(1.2V)は想定されていないことが若干心配だったんですが、残念ながらこの製品もニッケル水素電池が苦手そうです。
アルカリ乾電池を使うと4.9V 0.9Aくらいでほぼ定格出力しますが、ニッケル水素電池だと4.5V 0.8Aくらいまで電圧低下します。どちらも無負荷ならば5Vですから、ニッケル水素の電圧の低さが悪さをしているように思います。

上記の写真で充電しているデバイスはZenfone 4なんですけど、よくこの出力で充電できますね。期待している電圧より10%も低い(5Vを期待している)のに……。逆に凄いな。
充電効率はいかほどか?
充電できなくなった段階で、USB電力計は約1000mAhを表示していました。電圧が5Vでなくても、正確に測れているのかわかりませんが、表示を信じれば4.4V 1000mAh = 4.4Whくらい放電した計算です。
また、充電前の電池の電圧は1.23Vで、充電後の電池の電圧は1.15Vくらいでした(負荷30Ω)。ニッケル水素電池の終止電圧は1.0Vですから放電しきっていません(※2)。つまり、電池の表面に書いてある容量(1900mAh)は発揮できて「いません」。
ニッケル水素電池は1本1.2V 1900mAh = 2.28Wh、4本で9.12Whなので、48.2%しか使えておらず大変効率が悪いように見えますが、先も書いた通り終止電圧まで放電していないことによるロスと、DC-DC変換のロスがあるので、この数字だけ見て製品が悪いとは言えません。
乾電池タイプのモバイルバッテリーを使う場合、ニッケル水素電池からエネルギーを絞り切ることを目指すより、電池の数に物を言わせてガンガン入れ替えていく運用の方があっていそうですね。
(※2)終止電圧1.0Vに達した後、充電せずに放置すると完全放電してしまい電池がかなり傷むらしいので、使い切る前に止まってくれた方が嬉しい仕様だと思います。
コメント一覧
- コメントはありません。
この記事にコメントする
こんてんつ
wiki Linux JM Java API過去の日記
2002年 2003年 2004年 2005年 2006年 2007年 2008年 2009年 2010年 2011年 2012年 2013年 2014年 2015年 2016年 2017年 2018年 2019年 2020年 2021年 2022年 2023年 2024年 2025年 過去日記についてその他の情報
アクセス統計 サーバ一覧 サイトの情報