 未来から過去へ表示(*)
未来から過去へ表示(*) 2024年11月20日
nvJPEGとNVJPGとJetson APIその2 - nvJPEG simple decode API
目次: Linux
半年経ったら完全に忘れるのでメモします。最近JPEGのデコードエンコードが必要になって色々調べていました。NVIDIA GPUとCUDAを使ってJPEGが扱えるそうで、API名はnvJPEGだそうです(nvJPEGのAPIドキュメント)。
nvJPEG simple decoding
前回ご紹介したdecoupled decodingは呼び出すべきAPI数が多くて、ウワァ……と引いてしまう見た目でした。今回のsimple decodingはその名の通りシンプルです。ちなみにエンコード側もあります。なぜかsimpleに該当するAPIしかなく、decoupled相当のエンコード用APIは存在しないようです。変なの。
Simple decodingはこんな感じでした。Decoupledと比べるとかなりAPIが少なく済みます。
nvJPEG simple decodingのAPI呼び出し順
cudaStream_t stream = nullptr;
nvjpegHandle_t nvj_handle = nullptr;
nvjpegJpegState_t nvj_state = nullptr;
nvjpegImage_t outbuf = {0};
uint8_t *img_buf[4] = {nullptr};
int img_stride[4] = {0};
int img_sz[4] = {0};
int r;
// Create
cudaStreamCreateWithFlags(&stream, cudaStreamNonBlocking);
nvjpegCreateEx(NVJPEG_BACKEND_DEFAULT, nullptr, nullptr, NVJPEG_FLAGS_DEFAULT, &nvj_handle);
nvjpegJpegStateCreate(nvj_handle, &nvj_state);
//2のべき乗境界に切り上げる
#define ALIGN_2N(a, b) (((a) + (b) - 1) & ~((b) - 1))
outbuf.pitch[0] = ALIGN_2N(width, 256);
outbuf.pitch[1] = ALIGN_2N(width, 256);
outbuf.pitch[2] = ALIGN_2N(width, 256);
cudaMalloc(&outbuf.channel[0], outbuf.pitch[0] * height);
cudaMalloc(&outbuf.channel[1], outbuf.pitch[1] * height);
cudaMalloc(&outbuf.channel[2], outbuf.pitch[2] * height);
img_stride[0] = ALIGN_2N(width, 256);
img_stride[1] = ALIGN_2N(width, 256);
img_stride[2] = ALIGN_2N(width, 256);
img_buf[0] = (uint8_t *)malloc(img_stride[0] * height);
img_buf[1] = (uint8_t *)malloc(img_stride[1] * height);
img_buf[2] = (uint8_t *)malloc(img_stride[2] * height);
//Decoupled phase decoding
nvjpegGetImageInfo(nvj_handle, jpegbuf, jpegsize, &jpegcomps, &jpegsamp, jpegwidths, jpegheights);
nvjpegDecode(nvj_handle, nvj_state, jpegbuf, jpegsize, NVJPEG_OUTPUT_YUV, &outbuf, stream);
cudaStreamSynchronize(stream);
for (int i = 0; i < 3; i++) {
cudaMemcpy2D(img_buf[i], img_stride[i], outbuf.channel[i], outbuf.pitch[i],
width, height, cudaMemcpyDeviceToHost);
}
// Destroy
free(img_buf[0]);
free(img_buf[1]);
free(img_buf[2]);
cudaFree(outbuf.channel[0]);
cudaFree(outbuf.channel[1]);
cudaFree(outbuf.channel[2]);
nvjpegJpegStateDestroy(nvj_state);
nvjpegDestroy(nvj_handle);
cudaStreamDestroy(stream);
1枚だけJPEGをデコードするならこちらの方が断然楽ですね。
実行
前回同様にソースコードを置いておきます。
 nvJPEG simple decoding
nvJPEG simple decoding使い方はコードの先頭にコメントで書いている通りですが、ここでも説明しておきます。引数はありません。ファイル名test_420.jpgのJPEGファイルを読み込んで、ファイル名simple_420.yuvのRawvideoファイルを書き出します。
コンパイル、結果確認
$ g++ -g -O2 -Wall 20241120_nvjpeg_simple_dec.cpp -lnvjpeg -lcudart $ ./a.out $ ffplay -f rawvideo -video_size 1920x1440 -pixel_format yuv420p -i simple_420.yuv
デコード結果のRawvideoを確認するときはffplayを使うと便利です。
コメント一覧
- コメントはありません。
 この記事にコメントする
この記事にコメントする
2024年11月18日
nvJPEGとNVJPGとJetson APIその1 - nvJPEG decoupled API
目次: Linux
半年経ったら完全に忘れるのでメモします。最近JPEGのデコードエンコードが必要になって色々調べていました。NVIDIA GPUとCUDAを使ってJPEGが扱えるそうで、API名はnvJPEGだそうです(nvJPEGのAPIドキュメント)。それと別にJPEGのHWコーデックもあり、名前はNVJPG(Eがない)です。nvJPEGと紛らわしくて仕方ありません。
nvJPEG decoupled decoding
NVIDIAがnvJPEGのサンプルを公開しています(nvJPEGデコードサンプルコード)。ありがたいですね。でもなぜかサンプルはデコーダーしかありません。一応Resizeサンプルでエンコーダーを扱っていますが、なぜこんなサンプルの構造にしたのでしょう。
エンコード方法は公式ドキュメント(nvJPEGのドキュメント)の3.1.5 JPEG Encoding Exampleがシンプルで見やすいかもしれません。こちらはなぜかデコーダーのサンプルがありません。変なの。
困ったことにデコーダーのサンプルはRGBからYUVに変更すると動きません。試行錯誤したところストライドが間違っているようです。あとYUV420P(UとVプレーンの幅と高さはYプレーンの半分)なのに、YとUVが同じ高さじゃないとお気に召さないようでした。すなわち、
- ストライドを256バイトの倍数にする
- YUVの3プレーン全ての高さを同じにする
このようにするとデコードできました。ドキュメントに何も書いていないので、バグか合っているか全くわかりません。上記を考慮しつつDecoupled decodingする場合のAPI呼び出し順を載せておきます。
CUDA関連の謎APIについては、CUDA Stream Management(cudaStream_tなどのドキュメント)と、CUDA Memory Management(cudaMalloc()などのドキュメント)をご参照ください。
nvJPEG decoupled decodingのAPI呼び出し順
cudaStream_t stream = nullptr;
nvjpegHandle_t nvj_handle = nullptr;
nvjpegJpegState_t nvj_dcstate = nullptr;
nvjpegBufferPinned_t pinned_buffers[2] = {nullptr};
nvjpegBufferDevice_t device_buffer = nullptr;
nvjpegJpegStream_t jpeg_streams[2] = {nullptr};
nvjpegDecodeParams_t nvj_decparams = nullptr;
nvjpegJpegDecoder_t nvj_dec = nullptr;
nvjpegImage_t outbuf = {0};
uint8_t *img_buf[4] = {nullptr};
int img_stride[4] = {0};
int img_sz[4] = {0};
int r;
// Create
cudaStreamCreateWithFlags(&stream, cudaStreamNonBlocking);
nvjpegCreateEx(NVJPEG_BACKEND_DEFAULT, nullptr, nullptr, NVJPEG_FLAGS_DEFAULT, &nvj_handle);
nvjpegDecoderCreate(nvj_handle, NVJPEG_BACKEND_DEFAULT, &nvj_dec);
nvjpegDecoderStateCreate(nvj_handle, nvj_dec, &nvj_dcstate);
nvjpegBufferPinnedCreate(nvj_handle, nullptr, &pinned_buffers[0]);
nvjpegBufferPinnedCreate(nvj_handle, nullptr, &pinned_buffers[1]);
nvjpegBufferDeviceCreate(nvj_handle, nullptr, &device_buffer);
nvjpegJpegStreamCreate(nvj_handle, &jpeg_streams[0]);
nvjpegJpegStreamCreate(nvj_handle, &jpeg_streams[1]);
nvjpegDecodeParamsCreate(nvj_handle, &nvj_decparams);
//2のべき乗境界に切り上げる
#define ALIGN_2N(a, b) (((a) + (b) - 1) & ~((b) - 1))
outbuf.pitch[0] = ALIGN_2N(width, 256);
outbuf.pitch[1] = ALIGN_2N(width, 256);
outbuf.pitch[2] = ALIGN_2N(width, 256);
cudaMalloc(&outbuf.channel[0], outbuf.pitch[0] * height);
cudaMalloc(&outbuf.channel[1], outbuf.pitch[1] * height);
cudaMalloc(&outbuf.channel[2], outbuf.pitch[2] * height);
img_stride[0] = width;
img_stride[1] = width / 2;
img_stride[2] = width / 2;
img_sz[0] = img_stride[0] * height;
img_sz[1] = img_stride[1] * height / 2;
img_sz[2] = img_stride[2] * height / 2;
img_buf[0] = (uint8_t *)malloc(img_sz[0]);
img_buf[1] = (uint8_t *)malloc(img_sz[1]);
img_buf[2] = (uint8_t *)malloc(img_sz[2]);
//Decoupled phase decoding
nvjpegStateAttachDeviceBuffer(nvj_dcstate, device_buffer);
nvjpegOutputFormat_t fmt = NVJPEG_OUTPUT_YUV;
nvjpegDecodeParamsSetOutputFormat(nvj_decparams, fmt);
int index = 0;
nvjpegJpegStreamParse(nvj_handle, jpegbuf, jpegsize, 0, 0, jpeg_streams[index]);
nvjpegStateAttachPinnedBuffer(nvj_dcstate, pinned_buffers[index]);
nvjpegDecodeJpegHost(nvj_handle, nvj_dec, nvj_dcstate, nvj_decparams, jpeg_streams[index]);
nvjpegDecodeJpegTransferToDevice(nvj_handle, nvj_dec, nvj_dcstate, jpeg_streams[index], stream);
nvjpegDecodeJpegDevice(nvj_handle, nvj_dec, nvj_dcstate, &outbuf, stream);
cudaStreamSynchronize(stream);
for (int i = 0; i < 3; i++) {
cudaMemcpy2D(img_buf[i], img_stride[i], outbuf.channel[i], outbuf.pitch[i],
(i == 0) ? width : width / 2,
(i == 0) ? height : height / 2,
cudaMemcpyDeviceToHost);
}
// Destroy
free(img_buf[0]);
free(img_buf[1]);
free(img_buf[2]);
cudaFree(outbuf.channel[0]);
cudaFree(outbuf.channel[1]);
cudaFree(outbuf.channel[2]);
nvjpegDecodeParamsDestroy(nvj_decparams);
nvjpegJpegStreamDestroy(jpeg_streams[0]);
nvjpegJpegStreamDestroy(jpeg_streams[1]);
nvjpegBufferPinnedDestroy(pinned_buffers[0]);
nvjpegBufferPinnedDestroy(pinned_buffers[1]);
nvjpegBufferDeviceDestroy(device_buffer);
nvjpegJpegStateDestroy(nvj_dcstate);
nvjpegDecoderDestroy(nvj_dec);
nvjpegDestroy(nvj_handle);
cudaStreamDestroy(stream);
今回紹介したdecoupled decodingは速度が稼げるみたいですが、複雑です。もっと簡単なsimple decodingもあるので次回にご紹介しようと思います。
実行
ソースコードも置いておきます。
使い方はコードの先頭にコメントで書いている通りですが、ここでも説明しておきます。引数はありません。ファイル名test_420.jpgのJPEGファイルを読み込んで、ファイル名decoupled_420.yuvのRawvideoファイルを書き出します。
コンパイル、結果確認
$ g++ -g -O2 -Wall 20241118_nvjpeg_decoupled.cpp -lnvjpeg -lcudart $ ./a.out $ ffplay -f rawvideo -video_size 1920x1440 -pixel_format yuv420p -i decoupled_420.yuv
Rawvideoを確認するときはffplayを使うと便利です。FFMPEGは本当にありがたい。
コメント一覧
- コメントはありません。
この記事にコメントする
2024年11月17日
JTSA Limited大会参加2024
目次: 射的
JTSA Limitedの大会に参加しました。去年はベレッタが壊れましたが、今年は大丈夫でした。記録は絶好調というほどではありませんでしたが、自己ベストに近い71.65秒のタイムが出ました(総合79位/115人、LM 16位/26人)。さすがに3年目ともなると大会本番のまぐれ当たり&自己ベスト、なんて嬉しいアクシデントは発生しませんでした。
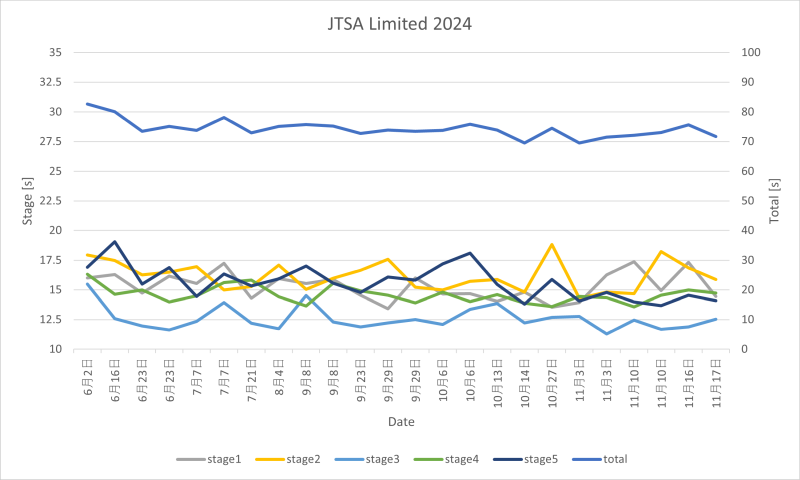
大会の記録だけ見ると、2022年85秒、2023年76秒、2024年71秒と順調に記録は伸びています。良きかな良きかな。来年はどうなるかな?
コメント一覧
- コメントはありません。
この記事にコメントする
| < | 2024 | > | ||||
| << | < | 11 | > | >> | ||
| 日 | 月 | 火 | 水 | 木 | 金 | 土 |
| - | - | - | - | - | 1 | 2 |
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
こんてんつ
wiki Linux JM Java API過去の日記
2002年 2003年 2004年 2005年 2006年 2007年 2008年 2009年 2010年 2011年 2012年 2013年 2014年 2015年 2016年 2017年 2018年 2019年 2020年 2021年 2022年 2023年 2024年 2025年 過去日記についてその他の情報
アクセス統計 サーバ一覧 サイトの情報
合計:
本日:
