 未来から過去へ表示(*)
未来から過去へ表示(*) 2023年9月22日
FizzBuzzを速くする2(高速アルゴリズムの紹介)
目次: ベンチマーク
FizzBuzzの実装は簡単ですが、可能な限り高速に出力しようとするとなかなか面白い遊びになります。前回は自作のアルゴリズムを紹介したので、今回は他の方が開発した高速化手法を紹介したいと思います。名前がないようなので、オフセット0xf6アルゴリズム(仮)と呼ぶことにします。
前回の最速(9桁10桁狙い撃ち+vmsplice)も含めて、ソースコードはGitHubに置いています(GitHubへのリンク)。
整数演算と文字列変換のトレードオフ
FizzBuzzの高速化の難しい点は、数値のインクリメント(=1ずつ増やす)と数字を文字列に変換する処理の両立です。単純な方法としては、現在の数値を整数で保持する方法、文字列で保持する方法が考えられます。
- 整数で保持: 演算は高速、文字列への変換は低速
- 文字列で保持: 演算は低速(繰り上がり処理にループが必要で遅い)、文字列変換は不要なので最速
どちらも一長一短で困りました。
整数演算と文字列変換の両立
このトレードオフを見事に解決しているのがオフセット0xf6アルゴリズム(仮)です。最初に要点を列挙しますと、
- 1バイト1桁(例えば64ビット変数なら8桁収まる)
- 各桁を0xf6でオフセット(0: 0xf6, 1: 0xf7, ..., 9: 0xff)
- 桁上がりするまでは数値のインクリメントは整数演算
- 桁上がりすると下の桁が全部0になるので、Trailing Zeroとマスク演算で0xf6をセットし直す
桁は1つ目に書いた通り、10進数1桁を1バイトで表現します。情報量としては過剰に見えますが文字列変換との両立のためです。
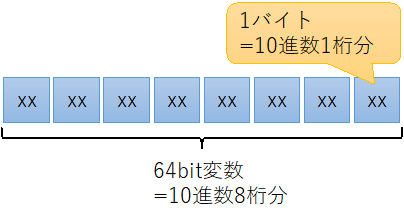
数の表現ですが0 = 0xf6, 1 = 0xf7, 2 = 0xf8, ... 9 = 0xffとします。10進数の123397ならば0xf6f6f7f8_f9f9fffdとなります。
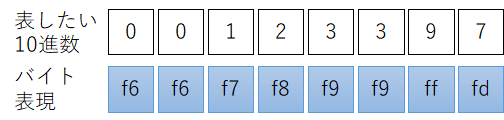
桁上がりするまで数値インクリメントは+1の整数演算で実現できます。
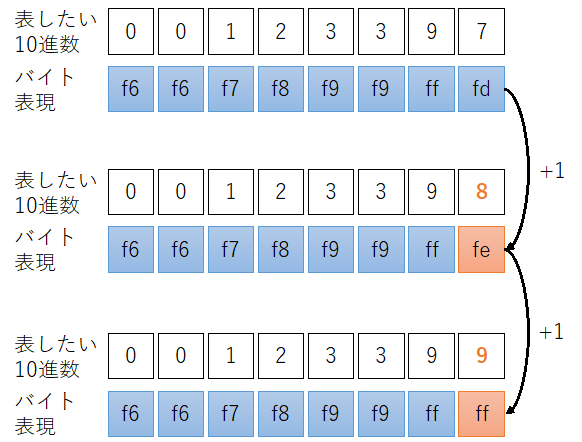
ここまではオフセットが変なだけの普通の整数です。
桁の繰り上がり処理
このアルゴリズムは桁の繰り上がり処理がエレガントで、+1の整数演算で適切な桁までの繰り上げが発生します。つまり加算命令1発で良く、ループ処理は必要ありません。先の例では下位の3桁が399から400になります。
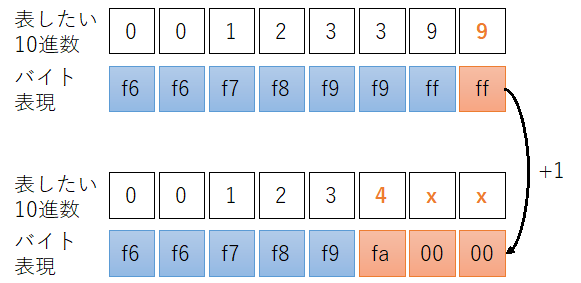
面倒な処理は不要で、+1の整数加算だけで、1の桁より上位の桁(この例だと10の桁も)が全て正しく繰り上がります。このアルゴリズムのナイスポイントその1です。
繰り上がった桁は値0x00になるので手当が必要です。先の例だと12399: 0xf6f6f7f8_f9f9ffffに+1すると、124xx: 0xf6f6f7f8_f9fa0000になって、下位の2桁(10の桁、1の桁)が無意味な値になっています。次の演算を行うには0x00の部分を10進数の0を意味する0xf6に戻す必要があります。
戻し方はまずCTZ (Count Trailing Zeros)で下位の連続している0のビット数を取得します。先の例ですと、下位24ビットが0xfa0000 = 0b1111_1010_0000_0000_0000_0000ですので、17ビットです。Nとします。
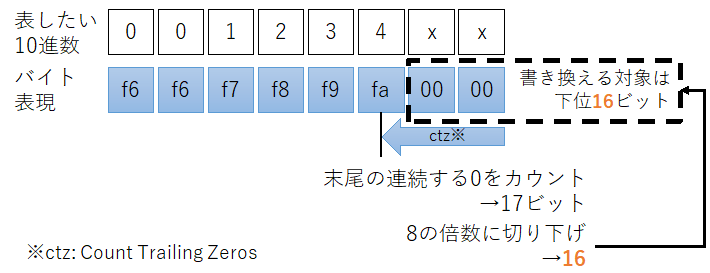
CTZビット数Nを8の倍数に切り下げ(= 16ビット)て、mask = (1 << N) - 1とし、下位16ビットに1がセットされた(= 0x00000000_0000ffff)マスクを作成します。その後(元の数値) |= 0xf6f6f6f6_f6f6f6f6 & maskを計算して、下位16ビットに0xf6をセットします。
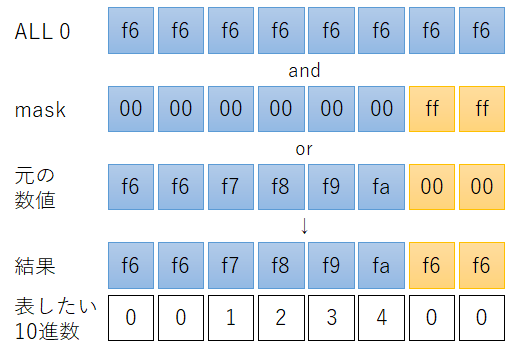
これで桁の繰り上げ処理は完了です。ループ処理は一切不要。アルゴリズムのナイスポイントその2です。
CTZにループが必要では?と思われるかもしれませんが、世の中には素敵なアルゴリズムがあってループなしで計算可能です。また現代のCPUはCTZ専用命令を持っていることが多く、基本命令の組み合わせより高速に処理できることが多いです。
文字列への変換
桁の繰り上がり処理の素晴らしさが伝わったところで、文字列への変換を紹介します。といっても極めて単純で高速です。0xc6c6c6c6_c6c6c6c6を減算するだけです。
一見すると意味不明ですが、ASCIIコードを考えるとわかると思います。0を表すバイト表現は0xf6でした。0xc6を引くと0xf6 - 0xc6 = 0x30になります。'0'はASCIIコードで0x30です。それだけで文字の'0'に変換できてしまいます。0以外の数値はどうなるかというと、
- 0: 0xf6 - 0xc6 = 0x30 = '0'
- 1: 0xf7 - 0xc6 = 0x31 = '1'
- 2: 0xf8 - 0xc6 = 0x32 = '2'
- ...
- 9: 0xff - 0xc6 = 0x39 = '9'
となります。他の位置のバイトも同様で、減算1回で8桁を8文字に変換できます。このアルゴリズムのナイスポイントその3です。
アルゴリズムとは関係ないですが、文字列をメモリに書くときはエンディアンに注意です。x86系CPUはリトルエンディアンなので、文字列に変換した64bit変数(0x30303132_33343938)をそのままメモリに書くと順序が逆転し、メモリには0x38 0x39 0x34 0x33 0x32 0x31 0x00 0x00、つまり"89432100"になります。
本当は"00123498"と書いてほしいので、メモリに書く前にビッグエンディアンに変換すれば良いです。この処理はバイトスワップと呼ばれたりします。これもループ不要の処理で、現代のCPUだと専用命令を持っている場合もあります。
以上がオフセット0xf6アルゴリズム(仮)のナイスポイントの紹介でした。いやあ、良く考え付いたなこれ。感心しました。
エレガントで速い
遅くなる要素は見当たりませんが、最後に測定しましょう。
オフセット0xf6のFizzBuzzの速度
# https://github.com/katsuster/fizzbuzz/blob/main/fizzbuzz2.c 33.3GiB 0:00:09 [3.39GiB/s] [ <=> ] real 0m9.824s user 0m7.447s sys 0m5.064s
約45倍まで速くなりました。素晴らしいです。
参考までに、前回私が作成した9桁10桁狙い撃ちの力業アルゴリズム(約42倍)はこのくらい。
9桁10桁狙い撃ちのFizzBuzzの速度
# https://github.com/katsuster/fizzbuzz/blob/main/fizzbuzz.c 33.3GiB 0:00:10 [3.16GiB/s] [ <=> ] real 0m10.543s user 0m8.921s sys 0m4.067s
ボロ負けというほど差は付いていませんが、コードのエレガントさは大いに差がありましたね。当たり前ですが、リングバッファやvmsplice()のような共通して使える工夫は双方で使いました。ですから純粋にFizzBuzz最適化アルゴリズムの差と言えましょう。
コメント一覧
- hdkさん(2023/09/23 14:56)
+1だから、繰り上がる時は必ず下のほうに0が固まるんですね。だから、CTZすらなくても、ビット演算と引き算などを組み合わせれば、分岐なしで、0になったところを0xf6で埋められるという... 賢い! Packed (8ビットで2桁分) でも同じ作戦はいけそうですね、ASCIIに変換するのが面倒にはなりますが。 - すずきさん(2023/09/23 21:14)
そうなんですよ。賢いなーと思って自分でも実装してみて、日記に書きました。桁の繰り上がりもさることながら、ASCIIへの変換が凄く速いのが特徴ですね。
 この記事にコメントする
この記事にコメントする
2023年9月21日
FizzBuzzを速くする1(自作アルゴリズム)
目次: ベンチマーク
FizzBuzzをご存じでしょうか?元々は英語圏の遊びで、1を最初にして、順に1ずつ足した数を宣言します。ただし3の倍数でFizz、5の倍数でBuzz、15の倍数でFizzBuzzと言わなければなりません。ルールはこれだけで単純です。試しに16まで書いてみるとこんな感じ。
FizzBuzz 1から16まで
1 2 Fizz 4 Buzz Fizz 7 8 Fizz Buzz 11 Fizz 13 14 FizzBuzz 16
FizzBuzzの実装は簡単ですが、可能な限り高速に出力しようとするとなかなか面白い遊びになります。自作、他作を含めて高速化の例を紹介したいと思います。
測定レギュレーション
FizzBuzzの実行範囲は1から2^32-2とします。すなわち1 ... 0xfffffffeです。出力される文字列は合計で33.3GBになります。
測定方法は簡単です。pvにパイプで繋いで出力の速度を表示します。速度が一定とは限らないので、並行してtimeで実行時間を測定します。出力が間違っていないかどうかテストするプログラムも必要ですが、本筋とは関係ないので省略します。
速度の測定方法
$ gcc -O3 something.c -o ./fizzbuzz && time taskset 0x1 ./fizzbuzz | taskset 0x4 pv > /dev/null
測定環境は、
- Intel Pentium J4205/1.5GHz
- DDR3L-1600 8GB x 2
- Linux kernel 6.1.52
- GCC 12.2.0 (Debian 12.2.0-14)
- glibc 2.36 (Debian 2.36-9+deb12u1)
いわゆる省電力PCで、そんなに速いPCではありません。
基準値
速度の絶対値とともに、一番単純な実装と高速化後で速度が何倍になったかを見ます。高速化のありがたみがわかりやすいでしょ?
単純なFizzBuzz
// fizzbuzz_simple.c
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char *argv[])
{
for (unsigned int i = 1; i < 0xffffffff; i++) {
if (i % 3 == 0 && i % 5 == 0) {
printf("FizzBuzz\n");
} else if (i % 3 == 0) {
printf("Fizz\n");
} else if (i % 5 == 0) {
printf("Buzz\n");
} else {
printf("%u\n", i);
}
}
return 0;
}
何も難しくないです。測定しましょう。
単純なFizzBuzzの速度
# fizzbuzz_simple.c 33.3GiB 0:07:32 [75.4MiB/s] [ <=> ] real 7m32.741s user 7m25.558s sys 0m51.090s
以降、この速度を基準値とします。
高速化その1 - printfを排除
プロファイリング(perf topなど)を見ると、printf()関連の処理に時間が掛かるようです。おそらく、
- libc内部のバッファリングが遅い?
- 毎回標準出力に書きだしていて遅い?
- 整数から文字列への汎用的な変換処理が遅い?
などが考えられます。対策として、
- リングバッファを実装、リングバッファ終端は少し余分に確保し、はみ出した分は先頭に折り返してコピー(ライトポインタの制御が最小限で済む)
- printf()の代わりにwrite()を使用、write()に与える単位をページ(4KB)の整数倍にする
- 整数から文字列への変換を10進数に限定して高速変換
以上を実装して測定します。整数から文字列への変換は、10000の剰余、10000で除算、を繰り返して4桁ずつ変換します。4桁の数字の変換は起動時に0000から9999までの1000要素のテーブルを作成しておいて、変換時はテーブルからコピーすることで高速化します。
printf排除FizzBuzzの速度
# fizzbuzz_myitoa.c 33.3GiB 0:01:20 [ 424MiB/s] [ <=> ] real 1m20.416s user 1m1.746s sys 0m21.756s
約6倍まで高速化しましたが、まだまだですね。
長い桁数を攻略
プロファイルを見ると整数から文字列への変換をする部分が遅いです。FizzBuzz実行範囲の1〜2^32-2にて最も多く出現し、かつ処理が遅い桁数は10桁、次いで9桁の数字です。遅い部分に集中して高速化します。
作っていて気づかれた方もいましょうが、FizzBuzzは15回で同じパターンがループします。つまり数字の桁数が同じであればFizzやBuzzが出てくるバイト位置も毎回同じのため、あらかじめ書いておくことができます。
最初に30回分のFizz, Buzz, FizzBuzzをあらかじめ書いておいた文字列をバッファにコピーします。数字が入る場所はドットで埋めてあります(後で書き換えるのでスペースでも何でも良い)。こんな感じです。
30回分のFizzBuzz(最初)
const char tmp10[] =
"FizzBuzz\n..........\n..........\n"
"Fizz\n..........\nBuzz\n"
"Fizz\n..........\n..........\n"
"Fizz\nBuzz\n..........\n"
"Fizz\n..........\n..........\n"
"FizzBuzz\n..........\n..........\n"
"Fizz\n..........\nBuzz\n"
"Fizz\n..........\n..........\n"
"Fizz\nBuzz\n..........\n"
"Fizz\n..........\n..........\n";
その後、数字を入れるべき個所を上書きします。例として4つ上書きした状態を示します。
30回分のFizzBuzz(途中)
"FizzBuzz\n1000000021\n1000000022\n"
"Fizz\n1000000024\nBuzz\n"
"Fizz\n1000000027\n..........\n"
"Fizz\nBuzz\n..........\n"
"Fizz\n..........\n..........\n"
"FizzBuzz\n..........\n..........\n"
"Fizz\n..........\nBuzz\n"
"Fizz\n..........\n..........\n"
"Fizz\nBuzz\n..........\n"
"Fizz\n..........\n..........\n";
なぜ15回分ではなく30回分かというと、10回分x 3に分解することができるからです。10回分をまとめるメリットとしては、10の桁より上の桁が全て同じ文字なので一度に書き換えられ、高速化が期待できることです。
コードは長いですが大して難しくないので、興味があればご覧ください。では速度を測ります。
9桁10桁狙い撃ちのFizzBuzzの速度
# fizzbuzz_9_10.c 33.3GiB 0:00:25 [1.31GiB/s] [ <=> ] real 0m25.372s user 0m10.515s sys 0m29.643s
約17倍まで高速化しました。いい感じです。
vmsplice
次はFizzBuzzの出口つまりpvコマンドへのパイプに着目します。今はwrite()を使っている状態で、write()でパイプに書き込むとカーネル内でパイプのメモリ領域へのデータコピーが発生して遅くなっています。
そう言われてもどうすれば?と思いますが、Linuxにはカーネル内のメモリコピー処理を省くためのシステムコールvmsplice()が存在します。
vmspliceの実装例
ssize_t vwrite(int fd, void *buf, size_t count)
{
struct iovec iov;
ssize_t n;
iov.iov_base = buf;
iov.iov_len = count;
while (iov.iov_len > 0) {
n = vmsplice(1, &iov, 1, 0);
iov.iov_base += n;
iov.iov_len -= n;
}
return count;
}
このようにvmsplice()を呼ぶvwrite関数を作成し、今までwrite()を呼んでいた個所を全てvwrite関数に置き換えます。
カーネル内の実装を調べていないため詳細な理由はわかりませんが、vmsplice()は動きにちょっと癖があってfcntl(F_SETPIPE_SZ)でパイプのサイズをある程度(64KB〜くらい?)大きくしないと、パイプの読み出し側でデータが壊れることがあります。
説明はこれくらいで測定しましょう。
vmspliceを使ったFizzBuzzの速度
# fizzbuzz_vmsplice.c 33.3GiB 0:00:10 [3.16GiB/s] [ <=> ] real 0m10.543s user 0m8.921s sys 0m4.067s
約42倍まで速くなりました。vmsplice()恐るべし。当初7分も掛かっていた2^32のFizzBuzzが、今やたったの10秒で終わるようになりました。
ソースコード
ソースコードはこちらからどうぞ。
 単純なFizzBuzz
単純なFizzBuzzコメント一覧
- コメントはありません。
この記事にコメントする
2023年9月18日
一覧の一覧 - まとめリンク
目次: 一覧の一覧
OS、アーキテクチャ系。
- 目次: Android
- 目次: Arduino
- 目次: ARM
- 目次: FreeRTOS
- 目次: Linux
- 目次: Raspberry Pi
- 目次: RISC-V
- 目次: Windows
- 目次: Zephyr
- 目次: 独自OS
C言語とかコンパイラ。
- 目次: apt
- 目次: ALSA
- 目次: C言語とlibc
- 目次: GCC
- 目次: Java
- 目次: LLVM
- 目次: OpenCL
- 目次: OpenOCD
- 目次: OpenPilot
- 目次: Python
- 目次: Yocto
- 目次: ベンチマーク
趣味、生活系。
- 目次: Kindle
- 目次: Might and Magicファミコン版
- 目次: PC
- 目次: STATIONflow
- 目次: ゲーム
- 目次: サンタ
- 目次: プロバイダ
- 目次: マンガ紹介
- 目次: 自宅サーバー
- 目次: 車
- 目次: 射的
- 目次: 電池
- 目次: ブラウザー/メーラー
コメント一覧
- コメントはありません。
この記事にコメントする
2023年9月15日
日本語とアルファベットの間にスペースを入れるのをやめた
目次: 自宅サーバー
私は昔からの癖で、文章を書くときに日本語と半角アルファベットの間に半角スペースを入れています。日本語と半角アルファベットが異様にくっついて表示されてしまう環境において、少しでも自然に見えるようにする姑息な手段です。
昔ならまだしも今となってはあまり意味がなく、そろそろやめようかなあと思っています。これから書く文章は自分の気持ち次第なのでどうにでもなりますが、今まで書いた日記はどうしようかな〜と悩んでいます。
根本治療は意外と難しい
過去の日記を眺めていましたが、一括の置換で直すのは結構大変そうです。基本的には「日本語と半角文字」もしくは「半角文字と日本語」の間にあるスペースを消すのですけど、例外的にスペースを維持したいパターンがあります。
- 削除したい: "この -a の項"のような場合の、-記号の前のスペース
- 削除したくない: "タイトル - サイト名"のような場合の、-記号の前後のスペース
残念なことに文脈依存なので区別が付きません。根本治療は諦めて下記の置換で簡易処置しました。
vim用の全バッファ置換コマンド
:bufdo %s/\([^a-zA-Z0-9 !-~]\) \([a-zA-Z0-9]\)/\1\2/gc :bufdo %s/\([a-zA-Z0-9]\) \([^a-zA-Z0-9 !-~]\)/\1\2/gc
どうしてもスペースの削除漏れが出るためか、ところどころバランスがおかしいですね……。元々あってもなくても良かったものですから、表示が大きく崩れるでもしない限りはこのままで良いでしょう。
コメント一覧
- コメントはありません。
この記事にコメントする
2023年9月11日
Windows - まとめリンク
目次: Windows
- Windows XPのブリッジ機能
- colinuxとWindowsのファイル共有
- .NET 2.0に嫌われた
- Windows PCの容量が足りません
- Windows XPを再インストール
- 使いづらいWindows 7のエクスプローラ
- 何もしていないのに負荷が高いWindows 7
- Windows 7のオーディオ処理負荷
- Windows 7のサウンド機能は辛いよ
- Sound Blaster X-Fiのサウンド設定いじってばっかり
- Sound Blaster X-Fiの話の訂正
- Sound Blaster X-Fiのドライバが劣化
- Windowsのスリープと仮想マシン
- Windows 7のファイルが壊れてた
- Windows Shellのショートカット処理の脆弱性
- 無線LANの故障かな?
- HDD破壊神Windows 10
- HDDクラッシャーは誰だ
- Windows 10の不思議なところ
- Windows 10の不思議なところ2
- 勝手に何かしているWindows 10
- Windows 10の謎のプロセス
- 勝手に何かしているWindows 10その2
- Windows 10のエクスプローラがクラッシュする
- Windows 10クラッシュの謎
- Windows 10遅くない?
- Windows 10とVirtualBox
- Windows 10 Fall Creators Update
- Windows 10クリーンインストール
- 音が出なくなったよWindows 10
- たまにズレちゃうWindows 10
- ノートPCの発熱を抑える方法 - その1
- ノートPCの発熱を抑える方法 - その2
- Windows 10謎の高負荷
- WindowsとLinuxのメモリ割り当て戦略の違い
- Windowsの仮想メモリサイズの謎
- このWindows PCはN年経過しています
- WindowsとRyzen 7 2700の動作周波数
- Windows PCの画面ロックを妨害(Windows API版)
- Windows PCの画面ロックを妨害(JavaScript版)
- デバイスを外してもずっとエラーが出るWindows 10
- Windows 10のタスクバーの困ったところ
目次: 一覧の一覧
コメント一覧
- コメントはありません。
この記事にコメントする
2023年9月10日
長物エアガン2号機M4A1カービン
目次: 射的
長物エアガンはスピードシューティングに全く向かないドラグノフしかありませんでしたが、もう少し撃ちやすいものも欲しいなと思って、東京マルイ M4A1カービン(メーカーの製品サイト)を購入しました。
長物はかなり高い(5万円くらいする)ことと、ハンドガンと違って家に置く場所がないので、いくつか買っていい感じのものを使う作戦が取れません。知識もありませんので、練習会でアドバイスをもらって素直におすすめされた機種を購入しました。おすすめされるだけあって撃ちやすいです。
大会で使うのはハンドガンなので、普段の練習会で使うというよりはイベントの時に活躍してもらうとしましょう。
コメント一覧
- コメントはありません。
この記事にコメントする
| < | 2023 | > | ||||
| << | < | 09 | > | >> | ||
| 日 | 月 | 火 | 水 | 木 | 金 | 土 |
| - | - | - | - | - | 1 | 2 |
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
こんてんつ
wiki Linux JM Java API過去の日記
2002年 2003年 2004年 2005年 2006年 2007年 2008年 2009年 2010年 2011年 2012年 2013年 2014年 2015年 2016年 2017年 2018年 2019年 2020年 2021年 2022年 2023年 2024年 2025年 2026年 過去日記についてその他の情報
アクセス統計 サーバ一覧 サイトの情報
合計:
本日:
