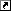 未来から過去へ表示(*)
未来から過去へ表示(*) 2023年3月10日
誕生日
ついに40歳の大台(?)に乗りました。
いわゆる老害というやつにならないように気をつけようと思っていますが、そもそも身近に若い人がいません。これは良いことなのか悪いことなのか??
今年のコロナはどうなるやら
COVID-19の感染者が増えたとき「第○波」と名付けられていたのは記憶に新しいと思います。大体のピーク時期は下記のようになっていました。(詳細は厚生労働省やNHKのデータをご覧ください)。ざっと4〜6ヶ月に1度に(= 年2〜3回)流行しており、今後も収束しなさそうですね。
- 第1波: 2020年5月ごろ
- 第2波: 2020年9月ごろ
- 第3波: 2021年2月ごろ
- 第4波: 2021年6月ごろ
- 第5波: 2021年9月ごろ
- 第6波: 2022年3月ごろ
- 第7波: 2022年9月ごろ
- 第8波: 2023年1月ごろ
全数把握は2022年の9月くらいで終わり、今後はインフルエンザと同じ扱いになっていくのでしょうか?COVID-19が今後どうなるか素人の私にはわかりませんが、災禍ないことを祈るばかりです。
ニューノーマル、ウィズコロナ
仕事のスタイルも大きく変わりました。勤務先では2020年の春くらいからリモートワークに切り替わり、現在も続いています。当初は、リモートワークなんて余裕余裕〜オフィスに出社しなくて良いなんてラッキー!満員の通勤電車滅びろ、くらいに思っていました。リモートワーク2年やってみて、考えは変わらないもののいくつか気づきもありました。
すぐに気づいたのは「通勤のため家の外に出かける」が意外と自分にとって大事だったことです。頭のモード?気持ち?の切り替えの役目を果たしていたらしく、リモートワークのときは気乗りしない日が増えました。
この話をすると、朝でも昼でも散歩に行けば?と言われますけど、そうじゃないんですね。「自主的」に外に行けるなら、やる気も自主的に出してます。家の外に出る「強制力」と「家の外に出かけることによるスイッチ効果」のコンビが大事だったみたいです。なので、今はたまに用事を作って会社に行く日を作っています。もちろん満員の通勤電車は要らないので滅びてOKなくなってどうぞ。
もうひとつ気づいたのは「社員がオフィスに集まっている状態」で暗黙のうちに得られる情報量の多さです。オフィスにみんなが居ると遠くの雑談が聞こえてきたり、話しかけなくても姿を見れば「忙しそうだ」とか「悩んでいる?」とか情報を得ることができました。リモートワークはそのような暗黙の視覚、聴覚情報が一切ありません。積極的に話しかけない限り、誰が何をしているのかわかりません。
この問題の解決方法はいくつかトライしてみましたが、あまりうまくいっていないように感じています。
- 定期的な雑談会議
- 雑談のために会議参加という行為が大げさ?面倒?あまり参加者がおらず過疎化しました。
- 繋ぎっぱなし&出入り自由の会議部屋
- 能動的に入ってくれる特定の人しか来ませんでした。音がして気が散るという意見もありました。深堀していませんがヘッドフォンだから?でしょうか……?
- カメラONを心がける
- (自分の試みではないですが)今もあまりカメラONにする人はいません。カメラONは背景に自分の家の部屋が映るのが気になるという意見もあり、心理的に抵抗が大きい(?)ようです。
- バーチャルオフィスサービス
- 出入り自由の会議部屋と似た状態になりつつあります。
社員がオフィスに集まっていたときは、何もアクションしない人にも受動的に情報が入ってきましたが、リモートワークだとなかなかそうはいきません。アクションする人としない人のコミュニケーション機会の差が開いてしまいます。
いやいや、オフィスを無理に再現しようとするから破綻が生じるのだ、潔く諦めチャットなどの文字ベースコミュニケーションをメインにせよ、という割り切りもあります。しかしそれも万能ではなく、文字ベースのコミュニケーションが明らかに苦手な人は放置なのか?どうケアするか?といった新たな問題が生じます。
今は各人、各企業の試行錯誤が続いているのだろうと思います、私は今の所これ!という解がありません。そのうち見つかるんですかねえ。
コメント一覧
- コメントはありません。
 この記事にコメントする
この記事にコメントする
2023年3月3日
Dockerのお掃除コマンド
目次: 自宅サーバー
Dockerを使っていると要らなくなったイメージ、コンテナ、ビルドキャッシュがたまってきて、/varディレクトリ以下が肥大化していることがあります。いつも忘れてしまうお掃除用のコマンドをメモしておきます。
各種お掃除方法と確認方法
### 終了しているcontainerの削除 $ docker container prune ### 確認 $ docker container ls -a ### タグもなく使われていないimageの削除 $ docker image prune ### 確認 $ docker image ls -a ### build cacheの削除 $ docker builder prune ### 確認 $ docker builder ls
Dockerがディスク容量をどの程度使用しているのかについてはsystem dfが便利(docker system dfのマニュアル)です。
使用済みディスク容量の確認
$ docker system df TYPE TOTAL ACTIVE SIZE RECLAIMABLE Images 1 1 14.26GB 0B (0%) Containers 2 1 0B 0B Local Volumes 0 0 0B 0B Build Cache 17 0 0B 0B
昔はコマンドの名前に一貫性がなかった記憶がありますが、今はxxx lsとすれば大抵の場合は一覧が出るため統一感があります。私のようなライトユーザーがやりたいと思う程度の機能は、大抵既に存在しており良くできていてありがたいです。
コメント一覧
- コメントはありません。
この記事にコメントする
2023年2月28日
SIMDを使ったお手軽最適化 - その2
目次: ベンチマーク
お手軽最適化のメモ、昨日の続きです。行列の掛け算を題材にします。前回は行列の掛け算と素朴な実装のコードを紹介しました。今回はお手軽最適化を紹介します。
スカラー処理だと遅いけれど、お手軽に最適化(数倍程度)がしたいときの参考になれば幸いです。
お手軽コース - 自動ベクトル化
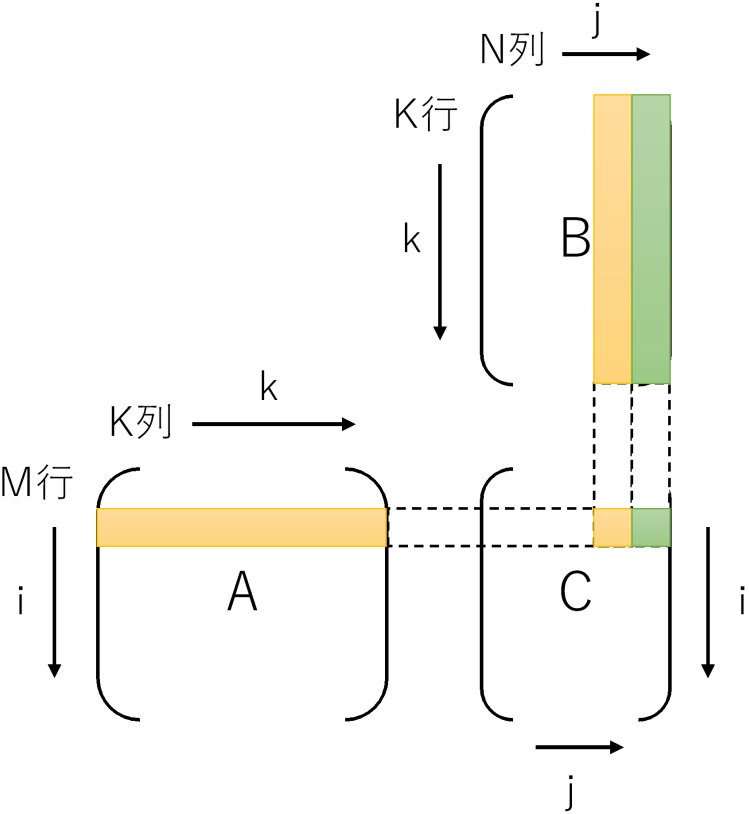
素朴版のコードですとi, j, kの順でループになっていて、kを最内ループにしていました。ループ内の計算は、
ループ内の計算式
c[i * nn + j] += a[i * kk + k] * b[k * nn + j]
でした。このときメモリアクセスのパターンは、
- A: 行方向に連続(メモリアクセスパターンは連続 = 自動ベクトル化できる)
- B: 列方向に連続(メモリアクセスパターンは飛び飛びアクセス = 自動ベクトル化できない)
- C: 同一要素を何度もアクセス
です。GCCの自動ベクトル化ですと、このアクセスパターンをうまく最適化できないようです。対象が最内ループのみなのかもしれません。ループを入れ替えjを最内にして、BとCを行方向に読むようにします。するとメモリアクセスのパターンは、
- A: 同一要素を何度もアクセス
- B: 行方向に連続(メモリアクセスパターンは連続 = 自動ベクトル化できる)
- C: 行方向に連続(メモリアクセスパターンは連続 = 自動ベクトル化できる)
です。ループを入れ替えるとループ内でCの0初期化ができないので、ループの外に追い出して最終的に下記のようなコードになります。
SGEMMループ入れ替え版
void sgemm_inner(const float *a, const float *b, float *c, int mm, int nn, int kk)
{
for (int i = 0; i < mm; i++) {
for (int j = 0; j < nn; j++) {
c[i * nn + j] = 0.0f;
}
}
for (int i = 0; i < mm; i++) {
for (int k = 0; k < kk; k++) {
for (int j = 0; j < nn; j++) { //★★jが最内ループ★★
c[i * nn + j] += a[i * kk + k] * b[k * nn + j];
}
}
}
}
SGEMMループ入れ替え版の実行時間
$ gcc -Wall -g -O2 -fno-tree-vectorize -static -march=znver3 sgemm.c $ ./a.out matrix size: M:1519, N:1517, K:1523 time: 1.528314 (参考: 素朴版の実行時間) time: 2.277758 (参考: OpenBLASシングルスレッドの実行時間) $ export OPENBLAS_NUM_THREADS=1 ----- use CBLAS verify: 0.052149
ループ入れ替えで倍くらい速くなっていますが、この最適化の本領はコンパイラの自動ベクトル化です。GCCならば -ftree-vectorizeオプションを指定すると、行列Bと行列CへのアクセスにSIMD命令を使うようになります。
Ryzen 7 5700Xの場合はAVX2命令を使えます。他のCPUをお使いの場合は -marchを適宜変更してください。
SGEMMループ入れ替え版+自動ベクトル化の実行時間
$ gcc -Wall -g -O2 -ftree-vectorize -static -march=znver3 sgemm.c $ ./a.out matrix size: M:1519, N:1517, K:1523 time: 0.181133 (参考: OpenBLASシングルスレッドの実行時間) $ export OPENBLAS_NUM_THREADS=1 ----- use CBLAS verify: 0.052149
素朴版とOpenBLASでは1/43もの差がありましたが、ループ入れ替えと自動ベクトル化によってOpenBLASの1/3.5程度まで近づきました。GEMMが計算偏重の処理で最適化の効果が出やすい、という点を考慮する必要はあるものの僅かな書き換えで得られる効果にしては割と良いのではないでしょうか。
もう少し頑張るコース - intrinsics
ソースコードを書き換える元気があれば、別の最適化方法もあります。GEMM特有の話に近付いてしまい、汎用的な話から遠ざかりますが、最適化ポイントの例という意味では参考になるはず……です。たぶん。
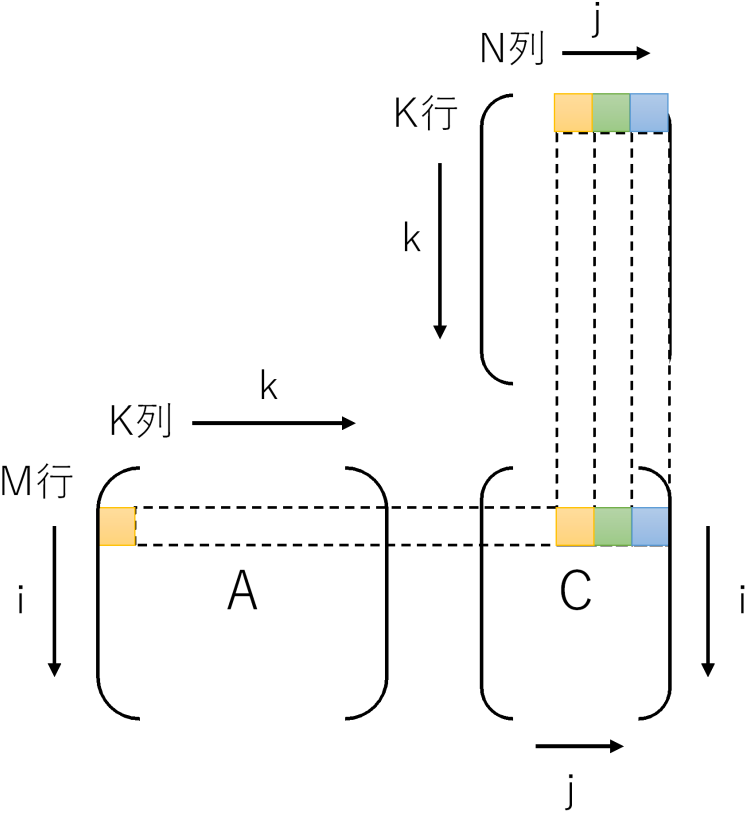
今回はSIMD命令でjの方向に一気に読むまでは同じですが、jの方向に進めるのではなく、kの方向に進めて、計算結果をCに足していく戦略です。具体的に言えばAi,kとBk,j〜Bk,j+7の8要素を一気に掛け算してCi,j〜Ci,j+7へ一気に足します。なぜ8要素かというとAVX/AVX2のレジスタ長(256bit)を使うと、32bit長のfloatを一度に8要素処理できるためです。
SIMD命令にはAi,kをSIMDレジスタの全要素に配る命令(set1_psから生成されるbroadcast命令)や、掛け算と足し算を一度に行うfmadd命令など、この計算順に最適な命令が揃っています。

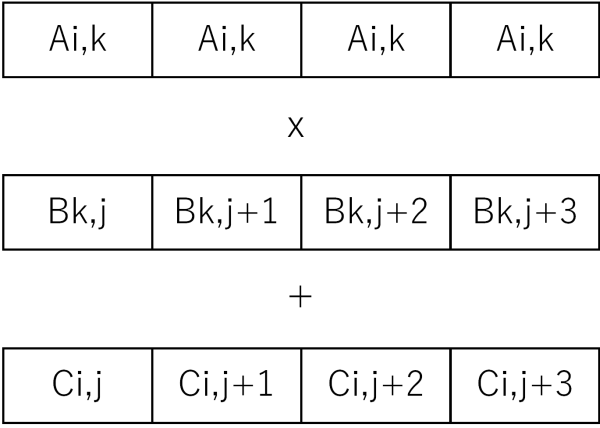
AVX/AVX2のIntrinsicsの詳細についてはIntelのサイトなどを見ていただくとして(Intel Intrinsics Guide)、コードは下記のようになります。
SGEMM Intrinsics版
#include <immintrin.h>
void sgemm_avx(const float *a, const float *b, float *c, int mm, int nn, int kk)
{
for (int j = 0; j < nn;) {
if (nn - j >= 8) {
for (int i = 0; i < mm; i++) {
__m256 vc = _mm256_set1_ps(0.0f);
for (int k = 0; k < kk; k++) {
__m256 va = _mm256_set1_ps(a[i * kk + k]);
__m256 vb = _mm256_loadu_ps(&b[k * nn + j]);
vc = _mm256_fmadd_ps(va, vb, vc);
}
_mm256_storeu_ps(&c[i * nn + j], vc);
}
j += 8;
} else {
for (int i = 0; i < mm; i++) {
c[i * nn + j] = 0.0f;
for (int k = 0; k < kk; k++) {
c[i * nn + j] += a[i * kk + k] * b[k * nn + j];
}
}
j++;
}
}
}
SGEMM Intrinsics版の実行時間
$ gcc -Wall -g -O2 -static -march=znver3 sgemm.c $ ./a.out matrix size: M:1519, N:1517, K:1523 time: 0.384861 (参考: 素朴版の実行時間) time: 2.277758 (参考: ループ入れ替え版+自動ベクトル化の実行時間) time: 0.181133 (参考: OpenBLASシングルスレッドの実行時間) $ export OPENBLAS_NUM_THREADS=1 ----- use CBLAS verify: 0.052149
素朴版と比べると6倍速いですが、ループ入れ替え+自動ベクトル化には負けています。
もう少し頑張るコース - ループアンローリング
先程のコードはSIMDレジスタを3個しか同時に使っていませんでした。AVX/AVX2のYMMレジスタは16個もあるのに3個しか使わないのはもったいですから、iのループを8要素ずつアンローリングしてSIMDレジスタを同時にたくさん使いましょう。レジスタをうまく使いまわせば12要素のアンローリング(Bの保持に1個、Cの保持に12個、Aの保持に1個、計14個)まではできそうです。たぶん。
SGEMM Intrinsics+ループアンローリング版
#include <immintrin.h>
void sgemm_avx_unroll8(const float *a, const float *b, float *c, int mm, int nn, int kk)
{
for (int j = 0; j < nn;) {
if (nn - j >= 8) {
int i = 0;
for (; i < (mm & ~7); i += 8) {
__m256 vc0 = _mm256_set1_ps(0.0f);
__m256 vc1 = _mm256_set1_ps(0.0f);
__m256 vc2 = _mm256_set1_ps(0.0f);
__m256 vc3 = _mm256_set1_ps(0.0f);
__m256 vc4 = _mm256_set1_ps(0.0f);
__m256 vc5 = _mm256_set1_ps(0.0f);
__m256 vc6 = _mm256_set1_ps(0.0f);
__m256 vc7 = _mm256_set1_ps(0.0f);
for (int k = 0; k < kk; k++) {
__m256 vb = _mm256_loadu_ps(&b[k * nn + j]);
__m256 va0 = _mm256_set1_ps(a[(i+0) * kk + k]);
__m256 va1 = _mm256_set1_ps(a[(i+1) * kk + k]);
__m256 va2 = _mm256_set1_ps(a[(i+2) * kk + k]);
__m256 va3 = _mm256_set1_ps(a[(i+3) * kk + k]);
__m256 va4 = _mm256_set1_ps(a[(i+4) * kk + k]);
__m256 va5 = _mm256_set1_ps(a[(i+5) * kk + k]);
__m256 va6 = _mm256_set1_ps(a[(i+6) * kk + k]);
__m256 va7 = _mm256_set1_ps(a[(i+7) * kk + k]);
vc0 = _mm256_fmadd_ps(va0, vb, vc0);
vc1 = _mm256_fmadd_ps(va1, vb, vc1);
vc2 = _mm256_fmadd_ps(va2, vb, vc2);
vc3 = _mm256_fmadd_ps(va3, vb, vc3);
vc4 = _mm256_fmadd_ps(va4, vb, vc4);
vc5 = _mm256_fmadd_ps(va5, vb, vc5);
vc6 = _mm256_fmadd_ps(va6, vb, vc6);
vc7 = _mm256_fmadd_ps(va7, vb, vc7);
}
_mm256_storeu_ps(&c[(i+0) * nn + j], vc0);
_mm256_storeu_ps(&c[(i+1) * nn + j], vc1);
_mm256_storeu_ps(&c[(i+2) * nn + j], vc2);
_mm256_storeu_ps(&c[(i+3) * nn + j], vc3);
_mm256_storeu_ps(&c[(i+4) * nn + j], vc4);
_mm256_storeu_ps(&c[(i+5) * nn + j], vc5);
_mm256_storeu_ps(&c[(i+6) * nn + j], vc6);
_mm256_storeu_ps(&c[(i+7) * nn + j], vc7);
}
for (; i < mm; i++) {
__m256 vc = _mm256_set1_ps(0.0f);
for (int k = 0; k < kk; k++) {
__m256 vb = _mm256_loadu_ps(&b[k * nn + j]);
__m256 va = _mm256_broadcast_ss(&a[(i+0) * kk + k]);
vc = _mm256_fmadd_ps(va, vb, vc);
}
_mm256_storeu_ps(&c[i * nn + j], vc);
}
j += 8;
} else {
for (int i = 0; i < mm; i++) {
c[i * nn + j] = 0.0f;
for (int k = 0; k < kk; k++) {
c[i * nn + j] += a[i * kk + k] * b[k * nn + j];
}
}
j++;
}
}
}
SGEMM Intrinsics+ループアンローリング版の実行時間
$ ./a.out matrix size: M:1519, N:1517, K:1523 time: 0.108420 (参考: ループ入れ替え版+自動ベクトル化の実行時間) time: 0.181133 (参考: OpenBLASシングルスレッドの実行時間) $ export OPENBLAS_NUM_THREADS=1 ----- use CBLAS verify: 0.052149
もはや最適化前のコードの原型がありませんが、ループ入れ替え版+自動ベクトル化の1.7倍くらいの速度になりました。OpenBLASの1/2程度まで迫っています。この最適化手法が汎用的か?と聞かれると何とも言えないですが、SIMDレジスタを同時にたくさん使う、最内ループ以外もアンローリング(最内ループはコンパイラがやってくれる)辺りは割と汎用的なアイデアです。
あと前回言った通り、GEMMは最適化の題材として取り上げただけなので、実際にGEMMを計算する場合はこのコードや自分で書いたコードを使うのではなく、信頼と実績のOpenBLASを使ってくださいませ。
コメント一覧
- コメントはありません。
この記事にコメントする
2023年2月27日
SIMDを使ったお手軽最適化 - その1
目次: ベンチマーク
お手軽最適化のメモです。行列の掛け算を題材にします。
最初にお断りしておくとGEMMのような汎用処理の場合は、自分で最適化せずにOpenBLASを使ってください(素人が最適化しても勝てません)。しかしOpenBLASのような限界まで最適化されたコードは誰でも簡単には書ける、とは言えません。
スカラー処理だと遅いけれど、お手軽に最適化(数倍程度)がしたいときの参考になれば幸いです。
GEMMってなんですか?
GEMMはGeneral Matrix Multiplyの略で、高校数学辺りでやった(はず)の行列の掛け算のことです。floatの場合はSGEMMと呼ばれ、doubleの場合はDGEMMと呼ばれます。最適化の題材はどちらでも良いんですけど、今回はSGEMMを使います。
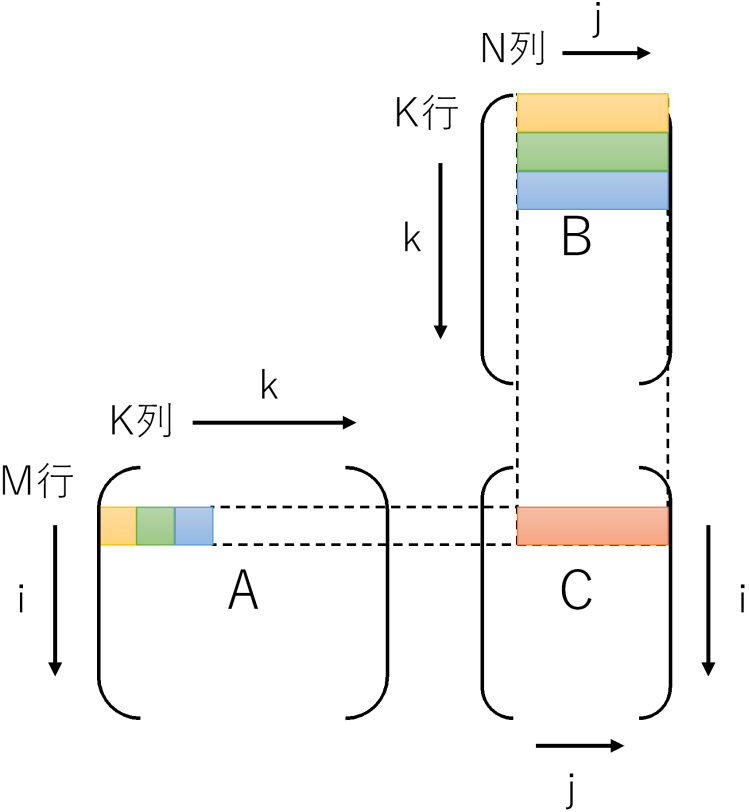
忘れている方のために2行3列の行列Aと3行2列Bの掛け算A x B = Cだとこんな感じです。
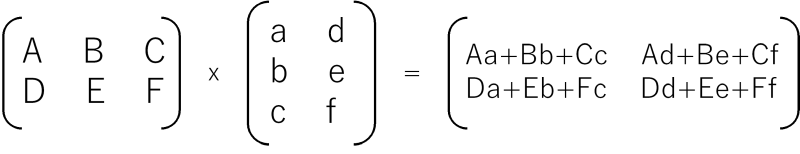
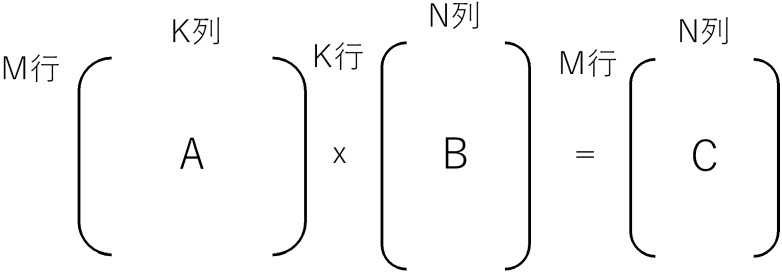
Aの列数とBの行数は一致していなければなりません。行数と列数の関係を表すと、行列A(M行K列)x行列B(K行N列)= 行列C(M行N列)となります。
Cの1要素を計算するには、Aの1行とBの1列が必要です。式、および、視覚的に示すと下記のようになります。
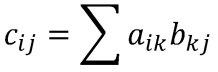
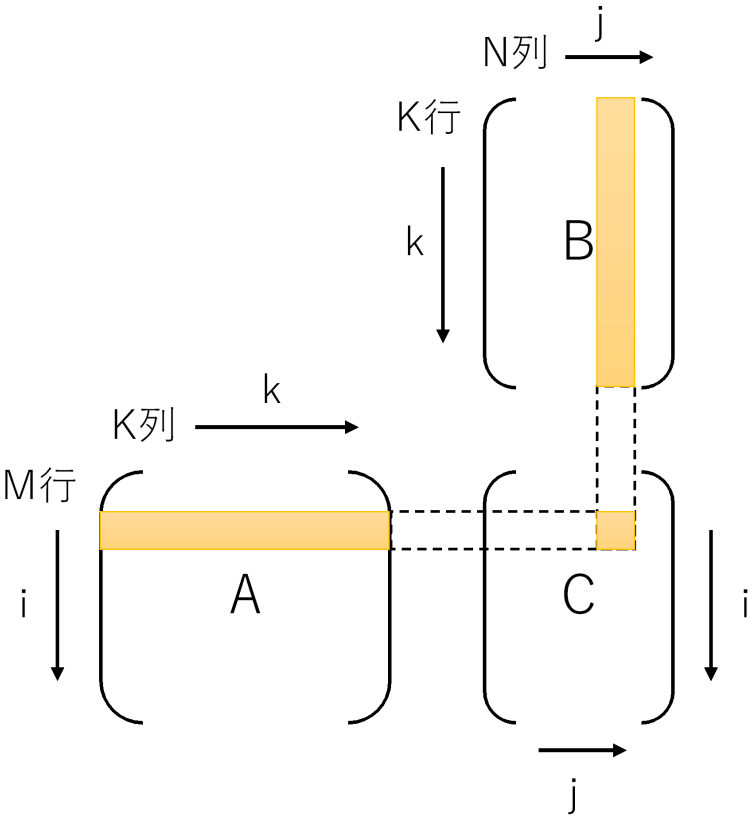
説明はこれくらいにしてコードを見ましょう。
基本コース - 素朴に演算
SGEMMを素直にコードにするとこんな感じです。行方向にデータを格納(Row-major orderといいます)しているので、N列の行列Cのi行j列(以降Ci,jと書く)にアクセスする際はc[i * N + j] とします。
SGEMM素朴版
void sgemm_naive(const float *a, const float *b, float *c, int mm, int nn, int kk)
{
for (int i = 0; i < mm; i++) {
for (int j = 0; j < nn; j++) {
c[i * nn + j] = 0.0f;
for (int k = 0; k < kk; k++) {
c[i * nn + j] += a[i * kk + k] * b[k * nn + j];
}
}
}
}
行列のサイズを適当に設定(M = 1519, N = 1517, K = 1523)して、実行時間を測ります。CPUはRyzen 7 5700Xです。
SGEMM素朴版の実行時間
$ gcc -Wall -g -O2 -static sgemm.c $ ./a.out matrix size: M:1519, N:1517, K:1523 time: 2.277758
実行時間は実行するたびに変わりますが、大体2.27秒くらいでしょうか。OpenBLASのシングルスレッド(環境変数OPENBLAS_NUM_THREADS=1にするとシングルスレッド動作になります)で計算した時間を見ると、
OpenBLASのSGEMMを呼ぶコード
c_ex = malloc(m * n * sizeof(float) * 2);
// C = alpha AB + beta C
float alpha = 1.0f, beta = 0.0f;
int lda = k, ldb = n, ldc = n;
printf("----- use CBLAS\n");
gettimeofday(&st, NULL);
cblas_sgemm(CblasRowMajor, CblasNoTrans, CblasNoTrans,
m, n, k, alpha, a, lda, b, ldb, beta, c_ex, ldc);
gettimeofday(&ed, NULL);
timersub(&ed, &st, &ela);
printf("verify: %d.%06d\n", (int)ela.tv_sec, (int)ela.tv_usec);
OpenBLASのSGEMM実行時間
$ export OPENBLAS_NUM_THREADS=1 $ gcc -Wall -g -O2 -static -L path/to/openblas/ sgemm.c -lopenblas $ ./a.out matrix size: M:1519, N:1517, K:1523 ----- use CBLAS verify: 0.052149
わずか0.05秒、実に43倍という驚異のスピードです。すごいですね……。
行列の掛け算の説明でほぼ終わってしまいました。お手軽最適化はまた次に。
コメント一覧
- コメントはありません。
この記事にコメントする
2023年2月25日
東京の道の名前
東京の道はようわからん通称(明治通り、みたいなやつ)が付いています。東京育ちの人にはなじみ深い名前だと思うんですが、都外出身者からすると、東京の道の通称と国道何号線、都道何号線の区分が全く合っていないので、知らない場所の道の通称を言われると結構困ります。
なぜかというと国道何号線、都道何号線という表記は地図で省かれることはない一方で、東京の道の通称は高速道路や地下鉄と重なったときに省かれてしまうことがあるためです。地図を見ても「〇〇通り?何それ?どこ??」と困惑します。
通称とは一体?
東京の道の通称は東京都が決めています(東京都通称道路名〜道路のわかりやすく親しみやすい名称〜 - 東京都建設局)。道案内の青看板に載るような名前と思ってもらえばわかりやすいでしょう。
東京都がまとめてくれているのはありがたいんですが「東京都が公式に定めた通称」というのは不思議な響きで、それは公称ではなかろうか?通称とは一体……??
なぜか存在しない大正通り
東京の道の通称には「年号」+「通り」という名前がいくつかあります。このうちなぜか大正通りだけは存在しません。不思議ですね。
- 江戸通り(No.26: 国道6号など、千代田区大手町二丁目〜台東区花川戸二丁目)
- 明治通り(No.3: 都道416, 306号など、港区南麻布二丁目〜江東区夢の島)
- 昭和通り(No.24: 国道4号など、港区新橋一丁目〜台東区根岸五丁目)
調べてみると割と有名な話らしいです(「明治通り」「昭和通り」はあるのに、なぜか「大正通り」はない東京のちょっとした謎 - アーバン ライフ メトロ)。詳しくは記事を読んでいただくとして、簡単に言えば、
- 東京日日新聞の公募で大正通りと呼ぼうとした(今の靖国通り)が定着せず
- 東京都の公募で靖国通りが選ばれた、東京都建設局のまとめる一覧に大正通りは入ってない
- 東京に「大正通り」はある(武蔵野市吉祥寺)
- 「平成通り」もある(中央区兜町〜築地二丁目)
- 「令和通り」はまだない
ということみたいです。
コメント一覧
- コメントはありません。
この記事にコメントする
| < | 2023 | > | ||||
| << | < | 03 | > | >> | ||
| 日 | 月 | 火 | 水 | 木 | 金 | 土 |
| - | - | - | 1 | 2 | 3 | 4 |
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 | - |
こんてんつ
wiki Linux JM Java API過去の日記
2002年 2003年 2004年 2005年 2006年 2007年 2008年 2009年 2010年 2011年 2012年 2013年 2014年 2015年 2016年 2017年 2018年 2019年 2020年 2021年 2022年 2023年 2024年 2025年 2026年 過去日記についてその他の情報
アクセス統計 サーバ一覧 サイトの情報
合計:
本日:
