2023年10月12日
FizzBuzzを速くする6(1桁落とし)
目次: ベンチマーク
FizzBuzzの実装は簡単ですが、可能な限り高速に出力しようとするとなかなか面白い遊びになります。以前紹介(2023年9月22日の日記参照)したオフセット0xf6アルゴリズム(仮)ですが、一番下の1桁を固定文字列と見なして削減するとさらに速くなります。
思いついたときは大して速くならないと予想しましたが、実装してみると意外に効き目がありました。やってみるものですね。せっかくなのでここに書き残しておきます。
基本戦略
FizzBuzzは15個を1つの単位として同じパターンが出現します。桁上がりを考えて30個を1単位とする最適化が良い、ことを自作アルゴリズムの紹介(2023年9月21日の日記参照)で説明しました。
さらに特定の桁数を狙い撃ちで最適化しましたが、オフセット0xf6アルゴリズム(仮)と相性が良くないようで残念ながら速くなりませんでした(2023年10月1日の日記参照)。
特定の桁数に依存しないように改良したのが今回紹介する方法です。名前がないと不便なので以降「1桁落とし」と呼びます。
1桁減らすメリット
その名の通り1桁減らした数 = 10で割った数を使います。30個単位で処理するときに数値を30ずつ増やしましたが、1桁落としでは3ずつ増やします。
なくなってしまった一番下の桁はFizzやBuzzと同様に固定的に出現する文字列として出力して補填します。何を言っているのか分かりにくいと思うので適当な数(1021〜1050)を例に考えましょう。
1021〜1050のFizzBuzz
102: ...1\n...2\nFizz\n...4\nBuzz\nFizz\n...7\n...8\nFizz\nBuzz\n 103: ...1\nFizz\n...3\n...4\nFizzBuzz\n...6\n...7\nFizz\n...9\nBuzz\n 104: Fizz\n...2\n...3\nFizz\nBuzz\n...6\nFizz\n...8\n...9\nFizzBuzz\n (注)"..."の部分には左端の数字が入る、と考えてください。
ドット(...)で示したところには数によって変わる部分で、それ以外の部分はどんな数字が来ても常に同じです。常に同じであれば、固定値を出力すれば良いので速くなるでしょう。
数字が10個進むまで上の桁は変わらないので、同じ文字列を何度も使いまわせます。数字から文字列への変換を何度も行わなくて良いので速くなるでしょう。
オフセット0xf6アルゴリズム(仮)への適用
オフセット0xf6アルゴリズムでは数字1個につき1回、文字列への変換をしていました。1桁落としを適用すると数字から文字列への変換は10個に1回で済みます。
10個分のFizzBuzz出力部分の抜粋&コメント
static void fizzbuzz30(struct dec *d, uint64_t j)
{
uint64_t h, l;
uint32_t wp_before = wp;
char *p = get_p();
char *p_s = p;
int r;
//数字から文字列への変換、hとlには文字列化された値が返る
//上位桁はこのあとずっと使いまわす
to_num(d, &h, &l);
//...1の上位桁出力
r = out_fixnum(p, d, h, l); p += r;
//...1の最下位桁出力(固定文字列)
r = out_two(p, "1\n"); p += r;
//...2の上位桁出力
r = out_fixnum(p, d, h, l); p += r;
//...2の最下位桁、Fizz出力(固定文字列)
r = out_2fizz(p); p += r;
//...4の上位桁出力
r = out_fixnum(p, d, h, l); p += r;
//...4の最下位桁、Buzz、Fizz出力(固定文字列)
r = out_4bandf(p); p += r;
//...7の上位桁出力
r = out_fixnum(p, d, h, l); p += r;
//...7の最下位桁出力(固定文字列)
r = out_two(p, "7\n"); p += r;
//...8の上位桁出力
r = out_fixnum(p, d, h, l); p += r;
//...8の最下位桁、Fizz、Buzz出力(固定文字列)
r = out_8fandb(p); p += r;
//桁上げ考慮したインクリメント(元の処理でいうと+10に相当)
inc_c(d);
数値から文字列への変換がなくなって、使いまわしの文字列出力と固定の文字列の羅列になります。これが結構速度に効くようです。命令そのものも減りますし分岐がほとんどなくなるから(?)でしょうか?
SSE命令と合わせ技
今回紹介した1桁落としと、前回紹介したSSE命令による最適化(2023年10月9日の日記参照)は独立したアイデアのため同時に適用できます。さらにハッピーです。
効き目を見たいので、1桁落とし+SSE命令版も実装します。
測定
省電力PC(CPU: Pentium J4205)で測定します。SSE版をビルドするときは-msse4.1オプションを付けてください。
Pentium J4205での実行結果
# 20231012_fizzbuzz_div10.c 33.3GiB 0:00:07 [4.22GiB/s] [ <=> ] real 0m7.898s user 0m6.260s sys 0m3.830s # 20231012_fizzbuzz_div10_sse.c 33.3GiB 0:00:06 [5.42GiB/s] [ <=> ] real 0m6.147s user 0m4.212s sys 0m4.243s
次はデスクトップPC(CPU: Ryzen 7 5700X)で測定します。
Ryzen 7 5700Xでの実行結果
# 20231012_fizzbuzz_div10.c 33.3GiB 0:00:01 [18.6GiB/s] [ <=> ] real 0m1.799s user 0m1.482s sys 0m1.089s # 20231012_fizzbuzz_div10_sse.c 33.3GiB 0:00:01 [19.1GiB/s] [ <=> ] real 0m1.744s user 0m1.480s sys 0m1.034s
前回測定分(2023年10月1日の日記参照)も含めて、時間と高速化の度合いをまとめると、
| FizzBuzzの種類 | Pentium J4205の実行時間 | 倍率 | Ryzen 7の実行時間 | 倍率 |
|---|---|---|---|---|
| 自前itoa | 1m6.621s | - | 15.759s | - |
| 30個まとめる | 38.860s | x1.7 | 9.152s | x1.7 |
| オフセット0xf6 | 9.671s | x6.8 | 2.063s | x7.6 |
| 1桁落とし | 7.898s | x8.4 | 1.799s | x8.7 |
| 1桁落とし+SSE命令 | 6.147s | x10.8 | 1.744s | x9.0 |
今回の測定では2^32 - 2までしか測っていませんが、もっと大きな数までFizzBuzzする場合、特定の桁数のみを狙った(前回は9桁と10桁に特化)最適化は桁数が変わると効果がなくなるのに対し、1桁落としならば何桁になっても効果があるのが嬉しいところです。
ソースコード
ソースコードはこちらからどうぞ。
 1桁落とし
1桁落としコメント一覧
- コメントはありません。
 この記事にコメントする
この記事にコメントする
2023年10月10日
マイクロアーキとシングルスレッド性能
目次: ベンチマーク
CPUマイクロアーキテクチャとシングルスレッド性能の傾向を見たいなあと思いたち、PassMarkのSingle Threadスコアを並べてみました。
- AMD系: Ryzen 7の無印となんとかXで終わる品番
- Intel系: Core i7のなんとかKで終わる品番
以上が横軸の選択基準です。絶対的な性能差はあまり気にせずに世代ごとの傾向を見ます。
AMD
Ryzen 7は階段状になるというのか、世代の変わり目がわかりやすいです。
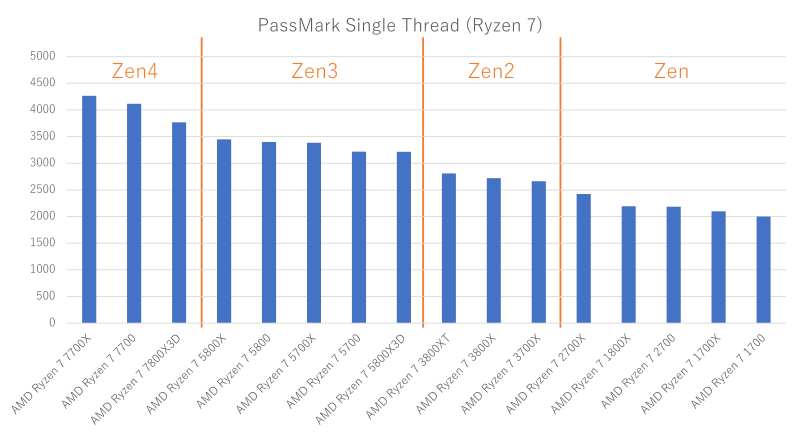
AMD Ryzen 7各モデルのシングルスレッド性能(クリックで拡大)
マイクロアーキテクチャの変更がシングルスレッド性能にかなり影響するのでしょうか。
Intel
Core i7は世代が多いのもあって階段状には見えないですね。Haswellの4GHzモデルが妙に速い(?)以外は、Ryzen 7同様に世代を経るにつれシングルスレッド性能が上がる傾向が見えます。
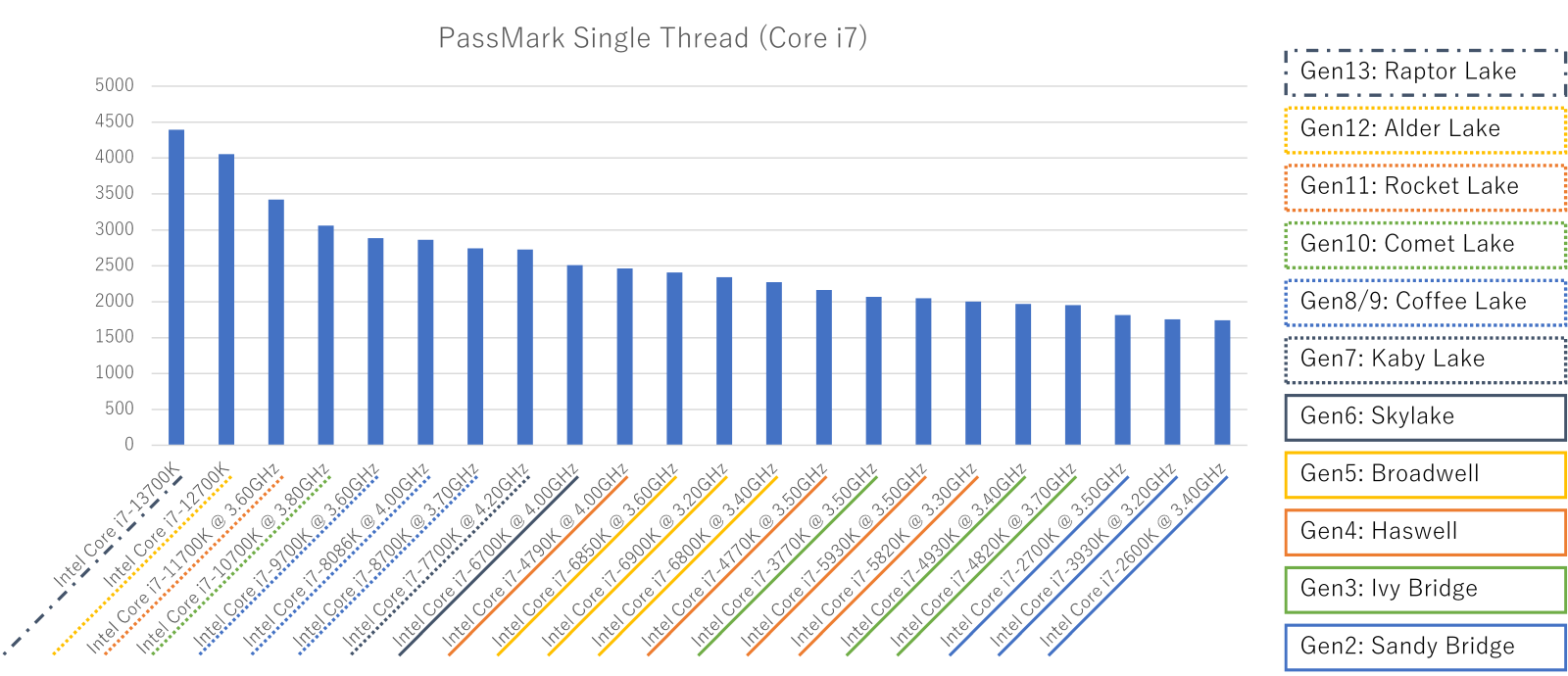
Intel Core i7各モデルのシングルスレッド性能(クリックで拡大)
Rocket Lakeまでの苦戦とAlder Lake & Raptor Lakeでの巻き返しが凄いです。
コメント一覧
- コメントはありません。
この記事にコメントする
2023年10月9日
FizzBuzzを速くする5(SIMD最適化の紹介)
目次: ベンチマーク
FizzBuzzの実装は簡単ですが、可能な限り高速に出力しようとするとなかなか面白い遊びになります。以前紹介(2023年9月22日の日記参照)したオフセット0xf6アルゴリズム(仮)ですが、SIMD命令(今回はSSE4.1を使います)を使って書き換えるとさらに速くなります。
この最適化は私が考えたものではなく、High throughput Fizz Buzz - Code Golf Stack Exchangeに投稿されていたxiver77さんのコードを元にしています。Cで書かれたコードでは最も高速のようです。
基本戦略
オフセット0xf6アルゴリズム(仮)では64bitで10進数の8桁を一度に計算しました。2^32全域を扱うには10桁必要なので、上8桁と下8桁に分けて繰り上がり処理が必要でした。SSEならレジスタ幅が128bitありますので16桁を一度に計算できます。良いですね。
基本戦略はオフセット0xf6アルゴリズム(仮)と一緒です。再掲します。
- 1バイト1桁(例えば64ビット変数なら8桁収まる)
- 各桁を0xf6でオフセット(0: 0xf6, 1: 0xf7, ..., 9: 0xff)
- 桁上がりするまでは数値のインクリメントは整数演算
- 桁上がりすると下の桁が全部0になるので、Trailing Zeroとマスク演算で0xf6をセットし直す
レジスタ幅が倍になって楽勝かと思いきや、SIMD命令には色々な制限があるので演算に工夫が必要です。
整数演算と桁上がりのSIMD化
値の初期化はnum = _mm_set1_epi8(0xf6)です。8ビットごとに0xf6を並べてくれます。
桁上がりしない場合は1を加算します。具体的には、num = _mm_add_epi64(num, _mm_set_epi64x(0, 1));です。_mm_set_epi64x(0, 1)は上位64bitに0、下位64bitに1をセットしています。ここまでは簡単ですね。
桁上がりする場合は少しややこしいです。下記のようなコードになります。
桁上がりのコード
static void inc_c(struct dec *d)
{
__m128i aaa;
//下位64bitに1を加算する
d->num = _mm_add_epi64(d->num, _mm_set_epi64x(0, 1));
//0と比較
// 等しい : 結果がAll 1(数値的には-1と同じ)
// 等しくない: 結果がAll 0(数値的には0と同じ)
aaa = _mm_cmpeq_epi64(d->num, _mm_setzero_si128());
//128bitの整数と見なして、8bytes = 64bit左シフト
// 下位64bitが0 : cmpeqの結果がAll 1、シフトで上位がAll 1 = -1
// 下位64bitが0以外: cmpeqの結果がAll 0、シフトで上位がAll 0 = 0
aaa = _mm_slli_si128(aaa, 8);
//減算する
d->num = _mm_sub_epi64(d->num, aaa);
//0x00を0xf6に置き換える
d->num = _mm_max_epu8(d->num, _mm_set1_epi8(0xf6));
}
始めに1を加算します。桁上がりが発生する場合は下位64bitが全て0になりますから、cmpeqで0と比較すれば桁上がりが発生している場合のみ下位64bitがAll 1つまり-1になります。
下位64bitを上位に左シフトして上位の値と減算すると桁上がり処理ができます。わかりにくいですね。図解しましょう。
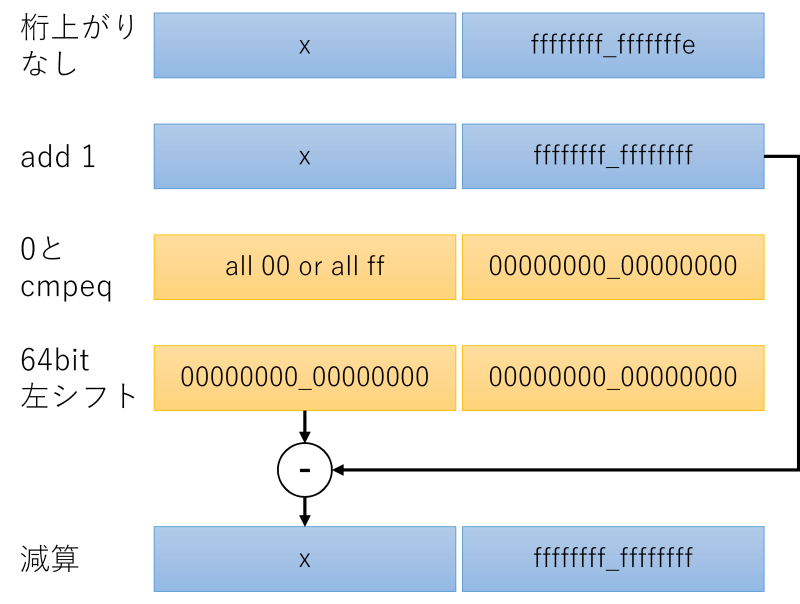
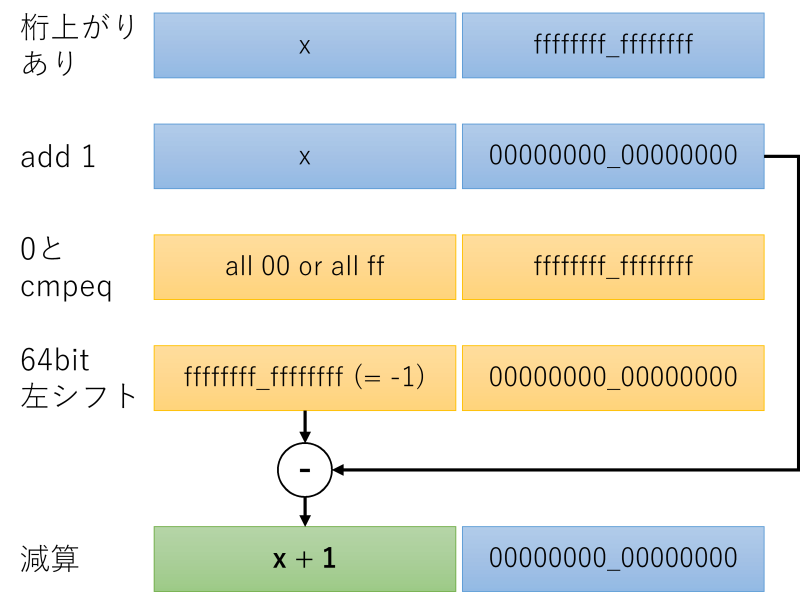
桁上がりで0x00になった部分を0xf6に戻す処理は、SSEには8bitごとにmaxを取れる命令があるので、一発で0x00→0xf6に置き換えできます。cmpeqとandとorでも置き換えられますが、数回試した限りどちらの実装も同じ速さに見えました。
文字列への変換
以前解説した通り、基本的には0xc6を減算、要らない桁を落とす、ビッグエンディアンに変換、の3つの処理を行います。こんなコードになります。
文字列への変換のコード
static int out_num(char *buf, struct dec *d)
{
__m128i aaa, bbb;
//8bitごとに0xc6を減算
aaa = _mm_sub_epi64(d->num, _mm_set1_epi8(0xc6));
//ビッグエンディアンに変換
bbb = _mm_set_epi64x(0x0001020304050607ULL, 0x08090a0b0c0d0e0fULL);
aaa = _mm_shuffle_epi8(aaa, bbb);
//書きこむ必要のない桁をシフトアウト
aaa = _mm_shuffle_epi8(aaa, mask_shuffle[16 - d->ke]);
_mm_storeu_si128((__m128i *)buf, aaa);
要らない桁を落とす処理は整数命令だと簡単でh <<= (落としたい桁数);のように左シフトで簡単に書けましたが、SSE命令だとちょっと厄介です。
さっき使った128bit左シフト_mm_slli_si128()を使えば良いのでは?と思いきや、実はSSEの128bitシフト命令はシフト幅が定数でなければなりません。可変値を指定するとコンパイルエラーになります。
_mm_slli_si128()のシフト幅に定数以外を指定したときのエラー
In file included from /usr/lib/gcc/x86_64-linux-gnu/12/include/xmmintrin.h:1316,
from /usr/lib/gcc/x86_64-linux-gnu/12/include/immintrin.h:31,
from 20231009_fizzbuzz_sse4.c:12:
In function ‘_mm_slli_si128’,
inlined from ‘inc_c’ at 20231009_fizzbuzz_sse4.c:105:8:
/usr/lib/gcc/x86_64-linux-gnu/12/include/emmintrin.h:1229:19: error: the last argument must be an 8-bit immediate
1229 | return (__m128i)__builtin_ia32_pslldqi128 (__A, __N * 8);
| ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
そのためシフトをshuffle命令で実現しています。コードが非常に見づらいですね……。
確かな性能
まずは省電力PC(CPU: Pentium J4205)で測定します。ビルドするときは-msse4.1オプションを付けてください。
Pentium J4205での実行結果
# 20231009_fizzbuzz_sse4.c 33.3GiB 0:00:06 [4.89GiB/s] [ <=> ] real 0m6.815s user 0m5.121s sys 0m3.616s
次はデスクトップPC(CPU: Ryzen 7 5700X)で測定します。
Ryzen 7 5700Xでの実行結果
# 20231009_fizzbuzz_sse4.c 33.3GiB 0:00:01 [18.0GiB/s] [ <=> ] real 0m1.857s user 0m1.604s sys 0m1.025s
前回測定分(2023年10月1日の日記参照)も含めて、時間と高速化の度合いをまとめると、
| FizzBuzzの種類 | Pentium J4205の実行時間 | 倍率 | Ryzen 7の実行時間 | 倍率 |
|---|---|---|---|---|
| 自前itoa | 1m6.621s | - | 15.759s | - |
| 30個まとめる | 38.860s | x1.7 | 9.152s | x1.7 |
| オフセット0xf6 | 9.671s | x6.8 | 2.063s | x7.6 |
| SSE命令 | 6.815s | x9.7 | 1.857s | x8.4 |
さすがSSE命令ですね。素晴らしい効き目です。
ソースコード
ソースコードはこちらからどうぞ。
コメント一覧
- コメントはありません。
この記事にコメントする
2023年10月7日
お葬式
横浜で大学の研究室の先輩のお葬式(正確には無宗教のお別れの会)がありました。突然の訃報にただただ驚き、悲しみを覚えるばかりでした。45歳は若すぎます……。喪主はお兄さんが務めておられました。お兄さんは初来日だそうですが、初来日が弟さんのお葬式なんて悲しすぎます……。英会話すると、自分の英語のヘボさと理解の怪しさをビシビシ感じます。
大学の研究室のみなさまと久しぶりに会えました。故人の思い出をたくさん話せたかなと思います。
リモートワーク
最近は毎日リモートワークの人も珍しくありませんが、1人暮らしor共働きで家人が居ないなどの場合、自宅で倒れてしまっても誰も気づけない欠点があることに気づかされました。だから全員毎日出社すべしとは思いませんけども、周りが気づける方法があると良いなとは思います。
横浜の道路は大渋滞
会場近くのお花屋さんで献花用のお花を買いたくて、徒歩より移動しやすかろうと車で向かったのは失敗でした。横浜横須賀道路が激しく渋滞していてかなり時間が掛かりました。周りの車を見ると埼玉?千葉?県外ナンバーばかりです、なぜこんなところに……って連休で遠出する人達かあ。3連休初日の朝であることを忘れていました。
会場までの所要時間が良くわからなかったので、1時間くらい余裕見て出発したのが功を奏し、幸いなことに遅刻はしませんでした。
コメント一覧
- コメントはありません。
この記事にコメントする
| < | 2023 | > | ||||
| << | < | 10 | > | >> | ||
| 日 | 月 | 火 | 水 | 木 | 金 | 土 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 | - | - | - | - |
最近のコメント20件
-
 24年10月1日
24年10月1日
すずきさん (10/06 03:41)
「xrdpで十分動作しているので、Wayl...」 -
24年10月1日
hdkさん (10/03 19:05)
「GNOMEをお使いでしたら今はWayla...」 -
24年10月1日
すずきさん (10/03 10:12)
「私は逆にVNCサーバーに繋ぐ使い方をした...」 -
24年10月1日
hdkさん (10/03 08:30)
「おー、面白いですね。xrdpはすでに立ち...」 -
14年6月13日
2048player...さん (09/26 01:04)
「最後に、この式を出すのに紙4枚(A4)も...」 -
14年6月13日
2048playerさん (09/26 01:00)
「今のところ最も簡略化した式です。\n--...」 -
14年6月13日
2048playerさん (09/16 01:00)
「返信ありがとうございます。\nコメントが...」 -
14年6月13日
すずきさん (09/12 21:19)
「コメントありがとうございます。同じ結果に...」 -
14年6月13日
2048playerさん (09/08 17:30)
「私も2048の最高スコアを求めたのですが...」 -
14年6月13日
2048さん (09/08 17:16)
「私も2048の最高スコアを求めたのですが...」 -
14年6月13日
2048playerさん (09/08 16:10)
「私も2048の最高スコアを求めたのですが...」 -
02年8月4日
lxbfYeaaさん (07/12 10:11)
「555」 -
24年6月17日
すずきさん (06/23 00:12)
「ありがとうございます。バルコニーではない...」 -
24年6月17日
hdkさん (06/22 22:08)
「GPSの最初の同期を取る時は見晴らしのい...」 -
24年5月16日
すずきさん (05/21 11:41)
「あー、確かにdpkg-reconfigu...」 -
24年5月16日
hdkさん (05/21 08:55)
「システム全体のlocale設定はDebi...」 -
24年5月17日
すずきさん (05/20 13:16)
「そうですねえ、普通はStandardなの...」 -
24年5月17日
hdkさん (05/19 07:45)
「なるほど、そういうことなんですね。Exc...」 -
24年5月17日
すずきさん (05/19 03:41)
「Standardだと下記の設定になってい...」 -
24年5月17日
hdkさん (05/18 22:16)
「ドメインを変えたせいで別サイト扱いになっ...」
最近の記事3件
こんてんつ
wiki Linux JM Java API過去の日記
2002年 2003年 2004年 2005年 2006年 2007年 2008年 2009年 2010年 2011年 2012年 2013年 2014年 2015年 2016年 2017年 2018年 2019年 2020年 2021年 2022年 2023年 2024年 過去日記についてその他の情報
アクセス統計 サーバ一覧 サイトの情報
合計:
本日:
