2021年5月29日
memsetのベンチマーク(RISC-V 64, U74-MC編)
目次: ベンチマーク
(参考)コード一式はGitHubに置きました(GitHubへのリンク)
Linuxが動くRISC-Vボードを買ったので、RISC-V 64でもmemsetをやってみました。環境はボードがSiFive HiFive Unmatchedで、SoCがSiFive Freedom U740で、コアがU74-MCです。動作周波数は書いてないですね。OSはSiFive独自?環境のFreedom USDKです。メモリはDDR4-2400のようです(Schematics hifive-unmatched-schematics-v3.pdfより)。
特徴的な点は、
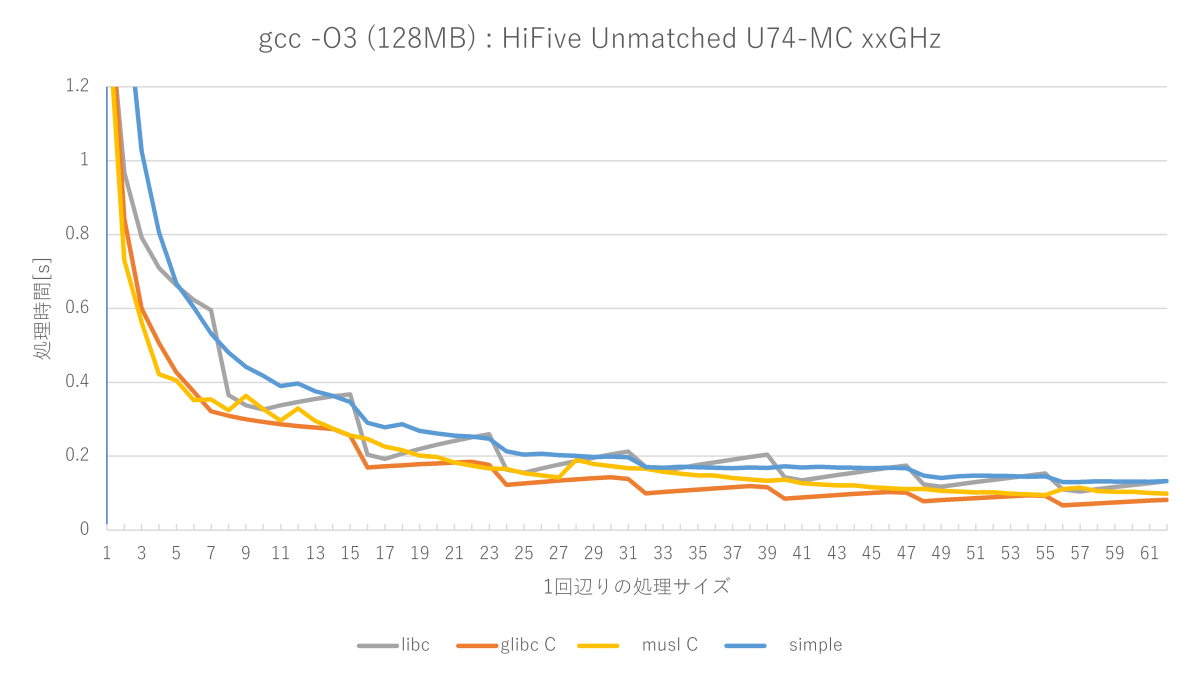
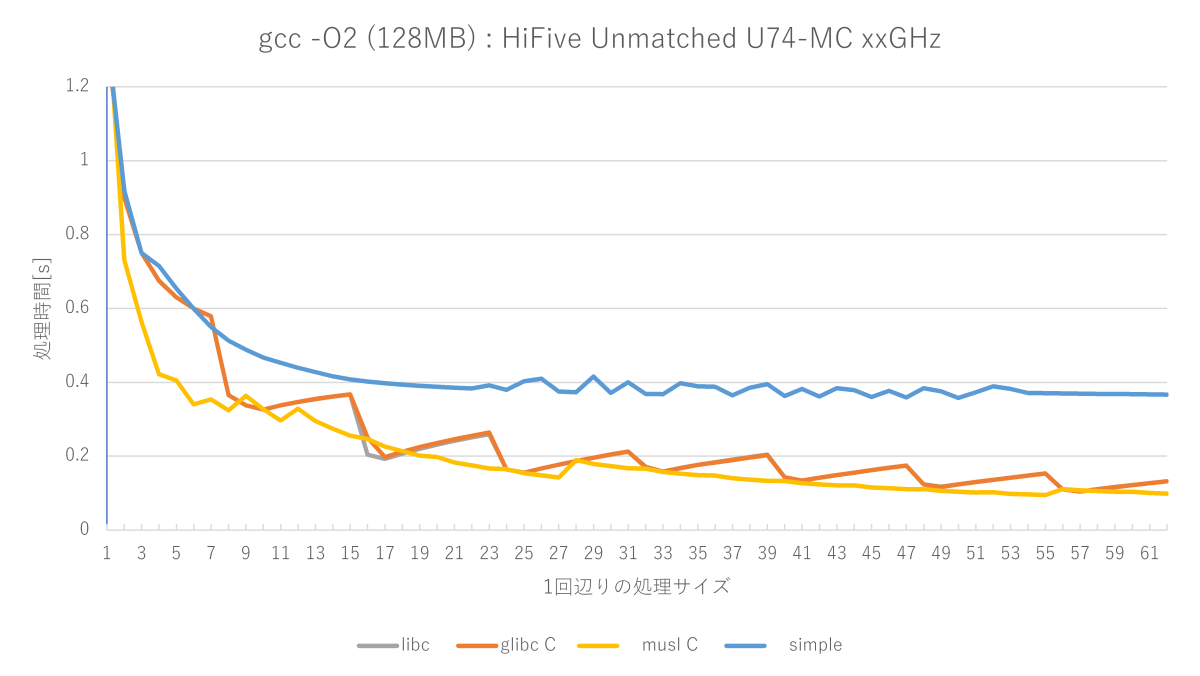
- glibc C実装が最速
- アセンブラ実装がない(O2のglibc C実装と同じ性能)
あと個人的に残念だった点としては、U74コアの速度です。前世代のHiFive Unleashedに搭載されていたU54コアはCortex-A53の足下にも及びませんでした(2019年5月27日の日記参照)。
U74はCortex-A72レベルとまでは言いませんが、Cortex-A53は超えてくると期待していましたが、少なくともmemsetに関しては負けています。半分くらいの速度しか出ていません……。
コメント一覧
- コメントはありません。
 この記事にコメントする
この記事にコメントする
2021年5月28日
RISC-V 64 CPU第2号が我が家に来た
目次: RISC-V
SiFiveのHiFive Unmatchedを購入しました。現状、世界最速のLinuxが動作するRISC-V 64bit SoC とのことです。
ボードにはSDカードが付属しておりSiFive独自環境のFreedom USDKがインストールされています。ボード上にはUSB接続のシリアル端子があり、電源を入れればLinuxが起動し、ユーザroot、パスワードsifiveでログインできるようになっています。
ぱっと見はPCと同じmini-ITXマザーボードですけど、バックパネルを見るとSDカードの差し込み口、USBシリアル用のmicroB端子が出ていて、どちらかといえばSBC(シングルボードコンピュータ)です。PCっぽさがありません。

本当はグラフィックカードを装着してGUIを使うべきですが、昨今のグラフィックカード品薄&異常な値上がりのおかげで全く買う気が起きないので、しばらくシリアルコンソールで使おうと思います。
インストールされているカーネルは、
Linux unmatched 5.11.10 #1 SMP Wed Apr 7 17:37:34 UTC 2021 riscv64 riscv64 riscv64 GNU/Linux
でした。5.11はStableカーネルではあるものの、既にEOLです。まあ、開発用ボードだしこんなもんか。
購入時の同じ罠
Crowd Supplyから購入しました。本体 $679, 消費税が7,100円、合計で7万円くらいでした。HiFive Unleashedほどではないにせよ、SBCにしては良いお値段です。
UPSが米国→日本まで持ってきて、国内はクロネコヤマトが運びます。受け取りの際に、消費税を着払いでクロネコに払う必要があります。私は消費税のことを忘れていて、何だこの金は??と混乱しました。Unleashedのときと全く同じでした。海外からものを買うことがほとんどなくて、消費税の存在をすぐ忘れちゃうんですよね……。
コメント一覧
- コメントはありません。
この記事にコメントする
2021年5月23日
TRONが世界標準??
Quoraのとある項目なぜTRON OSが「非常に優れていたが外圧で潰された」とか「組み込みで世界標準OSだ」とかいう誇張された伝説をいまだに信じている人が大勢いるのですか? - Quora が話題になっていました。そんな話を信じている人が居るんですね。TRONが世界標準……私の知らない世界線でTRONが覇権を獲ったのでしょうか……。
松下電器(おそらく日本一のTRON推しの会社でした)に居た自分すら、そんなこと思ったことありませんでした。
その松下電器でさえBTRONはもちろんiTRONすらギブアップです。いまやレコーダーやテレビのOSはLinux/BSDカーネルを採用しています。iTRONアプリも残ってはいますが、過去資産の作り直しは面倒&旨味がないのが理由だったと思います。
メモ: 技術系の話はFacebookから転記しておくことにした。
コメント一覧
- コメントはありません。
この記事にコメントする
2021年5月22日
ベンチマーク - まとめリンク
目次: ベンチマーク
色々なベンチマーク、コードゴルフ。
- USB HDD RAIDのベンチマーク
- ディスクI/Oベンチマークプログラム
- C言語でSEGV
- ELFバイナリでSEGVその1 - 92バイト
- ELFバイナリでSEGVその2 - 64バイト
- マイクロアーキとシングルスレッド性能
- 100万回のHello, World!
- 100万回のHello, World! - バイナリサイズを削って遊ぼう
- 100万回のHello, World! - バイナリサイズを削って遊ぼう、究極編その1
- 100万回のHello, World! - バイナリサイズを削って遊ぼう、究極編その2
- 100万回のHello, World! - バイナリサイズを削って遊ぼう、112バイトから104バイトへ
- 100万回のHello, World! - 補足
- Hello, World!のサイズを削る
アルゴリズム。
- ハフマン符号化プログラム
- ビット演算の極み(ハッカーのたのしみ)
- 最速のyes
- モナコイン
- 仮想通貨とマイニング
- モナコインとCubeHash
- ARMでCubeHash
- 不安定なyes
- デノーマルフラッシュ
- デノーマルフラッシュの速度改善効果
- 手動の最適化 対 コンパイラの最適化
- FizzBuzzを速くする1(自作アルゴリズム)
- FizzBuzzを速くする2(高速アルゴリズムの紹介)
- FizzBuzzを速くする3(CPUを変えてみよう)
- FizzBuzzを速くする4(うまくいかないこともある)
- FizzBuzzを速くする5(SIMD最適化の紹介)
- FizzBuzzを速くする6(1桁落とし)
- FizzBuzzを速くする7(コンパイラによる違い)
- yesの高速化(パイプ限定)
- SIMDを使ったお手軽最適化 - その1
- SIMDを使ったお手軽最適化 - その2
- C言語でNクイーン問題
- C言語でNクイーン問題、一意解
- C言語でNクイーン問題、高速化
- JavaScriptでNクイーン問題
- JavaScriptでNクイーン問題、その2
- スクリプト言語始めました(PythonとRubyでNクイーン問題)
- インタプリタon Java VM(PythonとRubyでNクイーン問題)
- CRCの計算方法 - その1
メモリクリアでおなじみmemset()関数の自作。
- memsetのベンチマーク(x86_64, Ryzen 7 2700編)
- memsetのベンチマーク(AArch64, Cortex-A72編)
- memsetのベンチマーク(AArch64, Cortex-A53編)
- memsetのベンチマーク(RISC-V 64, U74-MC編)
- muslのmemset関数
- memsetに一番効く最適化
- ぼくの考えた最強のmemset
- バイトをコピーするSIMD命令
- glibcのmemsetのクセ
- glibcのmemsetは強かった
目次: 一覧の一覧
コメント一覧
- コメントはありません。
この記事にコメントする
2021年5月16日
OpenCLのOSS実装poclを調べる その1 - 動かしてみよう
目次: OpenCL
最近OpenCLのオープンソース実装poclについて調べています。わかったことのメモです。
OpenCLはclGetDeviceIDs() を呼ぶときにデバイスの種類を指定します。KhronosのAPIドキュメント(clGetDeviceIDs(3) Manual Page)を見ると、デバイスの種類は4つ定義されています(DEFAULTとALLはデバイスの種類ではないので除外)。
- CL_DEVICE_TYPE_CPU
- OpenCLデバイスはホストCPUです。ホストCPUはシングルもしくはマルチコアCPUでOpenCLプログラムを実行します。OpenCLでマルチコアCPUの並列プログラムを書く人は居るのかな。あまり聞いたことがないですね……。
- CL_DEVICE_TYPE_GPU
- OpenCLデバイスはGPUです。GPUはOpenCLプログラムだけではなくて、OpenGLやDirectXのような3DグラフィクスAPIも高速に実行できます。GeForceやRadeonはこちらですね。
- CL_DEVICE_TYPE_ACCELERATOR
- OpenCLデバイスはアクセラレータ(例えばIBM CELL Blade)です。これらのデバイスはホストCPUとペリフェラル接続(PCI Expressなど)を使用して通信します。
- CL_DEVICE_TYPE_CUSTOM
- OpenCLデバイスはアクセラレータですが、OpenCL言語でカーネルを書くことができないタイプです。FPGAなんかが該当するんですかね?
これらのうちpoclがサポートしているのはCPUとGPUです。GPUはNVIDIAのCUDAとAMDのHSAに対応しているようです。全部LLVMがビルドしてくれるわけで、すごいよLLVMさん。ACCELERATORはテンプレート実装のみで、そのままでは動作しないので、注意が必要です。
ビルド、インストール
CPU(pthread版)、GPU(CUDA版)、ACCELERATORを有効にしたpoclのビルド、インストール方法は下記のとおりです。実際に動かすときはACCELERATORを無効にしてください。でないと初期化時にエラーが発生して動かないです。
poclのビルドとインストール
$ cmake -G Ninja \ -DCMAKE_INSTALL_PREFIX=`pwd`/_install \ -DENABLE_CUDA=ON \ -DENABLE_ACCEL_DEVICE=ON \ ../ $ ninja $ ninja install
基本的には必要なオプションがあればONにするだけですから、ビルドとインストールはそんなに難しくないはずです。
実行
実行方法はややクセがあります。OpenCLは実装がたくさんあるので、直接OpenCLライブラリをリンクするのではなく、ICD Loaderと呼ばれるライブラリ(2020年7月14日の日記参照)を間に噛ませることが多いです。
ソースコードは Oak Ridge大学のサイトとほぼ同じです。行数を減らしたのと、OpenCL 2.2に合わせて使うAPIを一部変えている程度です。
OpenCLのテスト用ソースコード
#define CL_TARGET_OPENCL_VERSION 220
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <CL/opencl.h>
// OpenCL kernel. Each work item takes care of one element of c
const char *kernelSource = "" \
"#pragma OPENCL EXTENSION cl_khr_fp64 : enable \n" \
"__kernel void vecAdd(__global double *a, \n" \
" __global double *b, \n" \
" __global double *c, \n" \
" const unsigned int n) \n" \
"{ \n" \
" // Get our global thread ID \n" \
" int id = get_global_id(0); \n" \
" \n" \
" // Make sure we do not go out of bounds \n" \
" if (id < n) \n" \
" c[id] = a[id] + b[id]; \n" \
"} \n" \
"\n" ;
int main(int argc, char *argv[])
{
// Length of vectors
int n = 100000;
size_t bytes = n * sizeof(double);
cl_platform_id cpPlatform;
cl_device_id device_id;
cl_context context;
cl_command_queue queue;
cl_program program;
cl_kernel kernel;
// Device input/output buffers
cl_mem d_a, d_b;
cl_mem d_c;
// Allocate memory for each vector on host
double *h_a = (double *)malloc(bytes);
double *h_b = (double *)malloc(bytes);
double *h_c = (double *)malloc(bytes);
// Initialize vectors on host
for (int i = 0; i < n; i++) {
h_a[i] = sinf(i) * sinf(i);
h_b[i] = cosf(i) * cosf(i);
}
// Number of work items in each local work group
size_t localSize = 64;
// Number of total work items - localSize must be devisor
size_t globalSize = ceil(n / (float)localSize) * localSize;
cl_int err;
// Bind to platform
err = clGetPlatformIDs(1, &cpPlatform, NULL);
if (err != CL_SUCCESS) {
printf("%s:%d err:%d\n", __func__, __LINE__, err);
return 0;
}
// Get ID for the device
err = clGetDeviceIDs(cpPlatform, CL_DEVICE_TYPE_CPU, 1, &device_id, NULL);
if (err != CL_SUCCESS) {
printf("%s:%d err:%d\n", __func__, __LINE__, err);
return 0;
}
// Create a context
context = clCreateContext(0, 1, &device_id, NULL, NULL, &err);
if (err != CL_SUCCESS) {
printf("%s:%d err:%d\n", __func__, __LINE__, err);
return 0;
}
queue = clCreateCommandQueueWithProperties(context, device_id, 0, &err);
if (err != CL_SUCCESS) {
printf("%s:%d err:%d\n", __func__, __LINE__, err);
return 0;
}
// Create the compute program from the source buffer
program = clCreateProgramWithSource(context, 1,
(const char **)&kernelSource, NULL, &err);
if (err != CL_SUCCESS) {
printf("%s:%d err:%d\n", __func__, __LINE__, err);
return 0;
}
// Build the program executable
err = clBuildProgram(program, 0, NULL, NULL, NULL, NULL);
if (err != CL_SUCCESS) {
printf("%s:%d err:%d\n", __func__, __LINE__, err);
return 0;
}
// Create the compute kernel in the program we wish to run
kernel = clCreateKernel(program, "vecAdd", &err);
if (err != CL_SUCCESS) {
printf("%s:%d err:%d\n", __func__, __LINE__, err);
return 0;
}
// Create the input and output arrays in device memory for our calculation
d_a = clCreateBuffer(context, CL_MEM_READ_ONLY, bytes, NULL, NULL);
d_b = clCreateBuffer(context, CL_MEM_READ_ONLY, bytes, NULL, NULL);
d_c = clCreateBuffer(context, CL_MEM_WRITE_ONLY, bytes, NULL, NULL);
// Write our data set into the input array in device memory
err = clEnqueueWriteBuffer(queue, d_a, CL_TRUE, 0,
bytes, h_a, 0, NULL, NULL);
if (err != CL_SUCCESS) {
printf("%s:%d err:%d\n", __func__, __LINE__, err);
return 0;
}
err = clEnqueueWriteBuffer(queue, d_b, CL_TRUE, 0,
bytes, h_b, 0, NULL, NULL);
if (err != CL_SUCCESS) {
printf("%s:%d err:%d\n", __func__, __LINE__, err);
return 0;
}
// Set the arguments to our compute kernel
err = clSetKernelArg(kernel, 0, sizeof(cl_mem), &d_a);
if (err != CL_SUCCESS) {
printf("%s:%d err:%d\n", __func__, __LINE__, err);
return 0;
}
err = clSetKernelArg(kernel, 1, sizeof(cl_mem), &d_b);
if (err != CL_SUCCESS) {
printf("%s:%d err:%d\n", __func__, __LINE__, err);
return 0;
}
err = clSetKernelArg(kernel, 2, sizeof(cl_mem), &d_c);
if (err != CL_SUCCESS) {
printf("%s:%d err:%d\n", __func__, __LINE__, err);
return 0;
}
err = clSetKernelArg(kernel, 3, sizeof(unsigned int), &n);
if (err != CL_SUCCESS) {
printf("%s:%d err:%d\n", __func__, __LINE__, err);
return 0;
}
// Execute the kernel over the entire range of the data set
err = clEnqueueNDRangeKernel(queue, kernel, 1, NULL,
&globalSize, &localSize, 0, NULL, NULL);
if (err != CL_SUCCESS) {
printf("%s:%d err:%d\n", __func__, __LINE__, err);
return 0;
}
// Wait for the command queue to get serviced before reading back results
clFinish(queue);
// Read the results from the device
clEnqueueReadBuffer(queue, d_c, CL_TRUE, 0,
bytes, h_c, 0, NULL, NULL);
//Sum up vector c and print result divided by n, this should equal 1 within error
double sum = 0;
for (int i = 0; i < n; i++) {
sum += h_c[i];
}
printf("final result: %f\n", sum / n);
clReleaseMemObject(d_a);
clReleaseMemObject(d_b);
clReleaseMemObject(d_c);
clReleaseProgram(program);
clReleaseKernel(kernel);
clReleaseCommandQueue(queue);
clReleaseContext(context);
free(h_a);
free(h_b);
free(h_c);
return 0;
}
poclの実行
$ gcc a.c -g -O0 -Wall -lOpenCL -lm ★ICD Loaderにpoclのライブラリ名を教える必要がある $ cat /etc/OpenCL/vendors/pocl_test.icd libpocl.so.2.7.0 $ LD_LIBRARY_PATH=/path/to/pocl/build/_install/lib \ ./a.out final result: 1.000000
動作しました。良かった。
OpenCLのAPIはICD Loaderが提供し、OpenCLの実装は各ICDが提供します。呼び出し関係はApp → ICD Loader → ICDです(詳しくは 2020年7月14日の日記参照)。一見すると煩雑ですが、アプリケーションはICDのことは知らなくても良いのが利点です。今回の例でいえばアプリケーションはlibpocl.soをリンクせずとも、poclの実装を使うことができます。
デバッグ
これだけだと面白くないし、何が動いているかすらわからないので、デバッグ出力を全開にして観察します。POCL_DEBUG環境変数を使います。その他のデバッグ方法はPoCLのドキュメント(Debugging OpenCL applications with PoCL)が参考になります。
poclのデバッグ出力(CUDA版)
$ LD_LIBRARY_PATH=/path/to/pocl/build/_install/lib \ POCL_DEBUG=all \ ./a.out ** Final POCL_DEBUG flags: FFFFFFFFFFFFFFFF [2021-03-13 07:05:14.074169726]POCL: in fn pocl_init_devices at line 571: | GENERAL | Installing SIGFPE handler... [2021-03-13 07:05:14.128006157]POCL: in fn pocl_cuda_init at line 287: | GENERAL | [CUDA] GPU architecture = sm_61 [2021-03-13 07:05:14.128050269]POCL: in fn findLibDevice at line 560: | CUDA | looking for libdevice at '/usr/lib/nvvm/libdevice/libdevice.10.bc' ...
動作しました。よきかな。タイムスタンプの日付がかなりズレますね……?ま、実害はないし良いか。
コメント一覧
- コメントはありません。
この記事にコメントする
| < | 2021 | > | ||||
| << | < | 05 | > | >> | ||
| 日 | 月 | 火 | 水 | 木 | 金 | 土 |
| - | - | - | - | - | - | 1 |
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 | - | - | - | - | - |
最近のコメント20件
-
 26年1月23日
26年1月23日
すずきさん (01/29 09:48)
「おおー、そんな昔からなんですね。歴史感じ...」 -
26年1月23日
hdkさん (01/27 19:53)
「#! はUNIX v8からだったってWi...」 -
24年12月9日
すずきさん (01/18 15:45)
「Thank you for your i...」 -
24年12月9日
Up2Uさん (01/15 12:57)
「Hi I also find the p...」 -
25年12月18日
すずきさん (12/23 23:51)
「良く見たらksys_read()でfil...」 -
25年12月18日
すずきさん (12/23 23:15)
「ですね、まあpread+readだと話が...」 -
25年12月18日
hdkさん (12/21 08:34)
「昔試しにデバイスドライバーを作ったことが...」 -
25年11月28日
hdkさん (12/04 08:10)
「あれ、停止直前くらいの時のトルクコンバー...」 -
25年11月28日
すずきさん (12/03 11:24)
「トルクコンバーターがいてエンブレは掛かり...」 -
25年11月28日
hdkさん (12/02 08:02)
「"停止直前に急にエンブレがほぼゼロになる...」 -
25年10月6日
すずきさん (10/10 13:14)
「ですね。ccはもはやコンパイラというより...」 -
25年10月6日
hdkさん (10/10 08:27)
「ただのHello, worldでも試して...」 -
25年9月29日
すずきさん (10/03 00:29)
「なんと、メタパッケージ入れてなかったです...」 -
25年9月29日
hdkさん (10/02 06:51)
「あれ、dkmsは自動ビルドされるのが便利...」 -
20年8月24日
すずきさん (08/30 22:06)
「ですね、自分も今はPulseAudioを...」 -
20年8月24日
hdkさん (08/29 09:32)
「ALSA懐かしい... PulseAud...」 -
16年2月14日
すずきさん (08/04 01:31)
「お役に立ったようでしたら幸いです。」 -
16年2月14日
enc28j60さん (08/03 17:40)
「ちょうど詰まっていたところです。\n非常...」 -
25年7月20日
すずきさん (07/30 00:10)
「ギクシャクするのは減速時の2速シフトダウ...」 -
25年7月20日
hdkさん (07/29 07:38)
「2速発進でギクシャクするんですか? 面白...」
最近の記事3件
こんてんつ
wiki Linux JM Java API過去の日記
2002年 2003年 2004年 2005年 2006年 2007年 2008年 2009年 2010年 2011年 2012年 2013年 2014年 2015年 2016年 2017年 2018年 2019年 2020年 2021年 2022年 2023年 2024年 2025年 2026年 過去日記についてその他の情報
アクセス統計 サーバ一覧 サイトの情報
合計:
本日:
