 未来から過去へ表示(*)
未来から過去へ表示(*) 2017年12月7日
Raspberry Pi 3とUART
今までRaspberry Pi 3にsshが繋がらなくなった時に、HDMIケーブルを繋いで画面を映していました。しかしディスプレイのHDMI端子は大抵、背面にあって接続が面倒です。
代わりにUSBシリアル変換ケーブルを買いました。PC側はUSB端子、Raspberry Pi側はGPIOピンヘッダに挿すだけで済みます。
うまく動いたのは良かったのですが、RasPiのピンヘッダがポッキリ折れそうで怖いです。この状態で常用するのは危ない気がしますね。世の中の人はどうしてるのかしら…??
コメント一覧
- コメントはありません。
 この記事にコメントする
この記事にコメントする
2017年12月6日
SHA-3
SHA-3に応募されたハッシュ関数の一覧です。SHA-3 2nd roundは下記のハッシュ関数が評価されました。(NIST IR 7764)
- BLAKE
- Blue Midnight Wish
- CubeHash
- ECHO
- Fugue
- Grøstl
- Hamsi
- JH
- Keccak
- Luffa
- Shabal
- SHAvite-3
- SIMD
- Skein
候補が絞られて、最終のSHA-3 3rd roundでは下記5つのハッシュ関数が評価されています。(NIST IR 7896)
- BLAKE
- Grøstl
- JH
- Keccak
- Skein
最終的にSHA-3に選ばれたのはKeccakです。
メモ: 技術系の話はFacebookから転記しておくことにした。
コメント一覧
- コメントはありません。
この記事にコメントする
2017年12月3日
ハッシュ関数とSIMD演算
CubeHashはSIMD演算が非常に有効なアルゴリズムでしたが、他のハッシュ関数をざっと見た感じSIMD演算にできる箇所があまりなく、速くならなさそうです。
今回のようにSIMDでハッシュ計算の速度を4倍にする方向に頑張るのはアルゴリズムに大きく依存するので、応用が効きません。
ハッシュ検索がお互いに独立していることを利用し、SIMDのレジスタにA, B, C, Dの4つのハッシュを入れて、4つのハッシュを同時に演算する方が応用範囲が広いです。
しかしこの方法も万能では無いです。
問題その1は、ワーク領域が16で済むアルゴリズムは無いので、明らかにx64の16レジスタではレジスタ数が足りません。L1キャッシュ頑張れ。
問題その2は、ワーク領域の内容を条件とする、条件分岐処理がほぼ不可能になることです。例えばSIMDレジスタにA, B, C, Dの4つのハッシュを入れて、4つ同時に計算しているとしましょう。こんな処理がアルゴリズムに入っていたとき、
if (w == 0)
w++;
else
w--;
SIMD命令をどう書くのが正解でしょうか?デクリメント?インクリメント?
わかりやすくするため、A, B, Dのワーク領域は0以外、Cのワーク領域だけが0だったとします。
もしデクリメント命令を書けばA, B, Dは正しいですが、Cの結果はおかしくなります。逆にインクリメント命令を書けばCは正しいですが、A, B, Dの結果はおかしくなります。従って「記述は不可能」が答えです。
もしSIMD演算命令に一部フィールドだけ(例えばCだけ、とか)演算するような特殊な命令があれば話は変わりますが、通常、分岐の実装は不可能です。
ちなみに、検索していたら、SIMDによる並列演算に成功されている方がいました。CubeHashはもちろんkeccak, BLAKE2, skeinはAVX2で大層速くなるそうです。しかも半年ほど前に実装までされていました。すっごいなこの人…!
モナコイン界隈で有名な人らしくてASK Monaという掲示板でccminer(CUDAを使ったマイナー)を速くしたり、sgminer(OpenCLを使ったマイナー)を速くしている方のようです。
メモ: 技術系の話はFacebookから転記しておくことにした。
コメント一覧
- コメントはありません。
この記事にコメントする
2017年12月1日
ARMでCubeHash
先日(2017年11月30日の日記参照)CPUによるモナコインというかLyra2REv2の計算で、ボトルネックとなっていたCubeHashをSSE化してみました。今回はARMでチャレンジしてみます。
Raspberry Pi 3(ARM Cortex A53/1.2GHz x 4)でCPUマイナーを実行してみるとたったの8kH/sしか出ません。4コア並列で動作させると32kH/sとなり、きっちり4倍になるのは素晴らしい(※)ですが、x86_64 CPUの1コアにも敵わないです。
NEONにもIntrinsicsがあることを知ったので、不親切なNEON命令のマニュアルと戦いながら、CubeHashをNEON化してみたところ、10kH/sほどになりました。
NEONを使ったCubeHashの素朴な実装
#if defined(__ARM_NEON__)
# include <arm_neon.h>
#endif
//...
#define NEON_ROTL(x, n) do { \
uint32x4_t mw0, mw1; \
mw0 = vshlq_n_u32((x), (n)); \
mw1 = vshrq_n_u32((x), 32 - (n)); \
x = vorrq_u32(mw0, mw1); \
} while (0);
#define NEON_SWP(a, b) do { \
uint32x4_t mw; \
mw = b; \
b = a; \
a = mw; \
} while (0);
#define NEON_STEP5(x) do { \
uint64x2_t mw; \
mw = vreinterpretq_u64_u32((x)); \
mw = vextq_u64(mw, mw, 1); \
x = vreinterpretq_u32_u64(mw); \
} while (0);
#define ROUND_ONE_NEON do { \
mxg = vaddq_u32(mx0, mxg); \
mxk = vaddq_u32(mx4, mxk); \
mxo = vaddq_u32(mx8, mxo); \
mxs = vaddq_u32(mxc, mxs); \
NEON_ROTL(mx0, 7); \
NEON_ROTL(mx4, 7); \
NEON_ROTL(mx8, 7); \
NEON_ROTL(mxc, 7); \
NEON_SWP(mx0, mx8); \
NEON_SWP(mx4, mxc); \
mx0 = veorq_u32(mx0, mxg); \
mx4 = veorq_u32(mx4, mxk); \
mx8 = veorq_u32(mx8, mxo); \
mxc = veorq_u32(mxc, mxs); \
NEON_STEP5(mxg); \
NEON_STEP5(mxk); \
NEON_STEP5(mxo); \
NEON_STEP5(mxs); \
mxg = vaddq_u32(mx0, mxg); \
mxk = vaddq_u32(mx4, mxk); \
mxo = vaddq_u32(mx8, mxo); \
mxs = vaddq_u32(mxc, mxs); \
NEON_ROTL(mx0, 11); \
NEON_ROTL(mx4, 11); \
NEON_ROTL(mx8, 11); \
NEON_ROTL(mxc, 11); \
NEON_SWP(mx0, mx4); \
NEON_SWP(mx8, mxc); \
mx0 = veorq_u32(mx0, mxg); \
mx4 = veorq_u32(mx4, mxk); \
mx8 = veorq_u32(mx8, mxo); \
mxc = veorq_u32(mxc, mxs); \
mxg = vrev64q_u32(mxg); \
mxk = vrev64q_u32(mxk); \
mxo = vrev64q_u32(mxo); \
mxs = vrev64q_u32(mxs); \
} while (0)
#define SIXTEEN_ROUNDS_NEON do { \
int j; \
uint32x4_t mx0, mx4, mx8, mxc; \
uint32x4_t mxg, mxk, mxo, mxs; \
mx0 = vld1q_u32((void *)&x0); \
mx4 = vld1q_u32((void *)&x4); \
mx8 = vld1q_u32((void *)&x8); \
mxc = vld1q_u32((void *)&xc); \
mxg = vld1q_u32((void *)&xg); \
mxk = vld1q_u32((void *)&xk); \
mxo = vld1q_u32((void *)&xo); \
mxs = vld1q_u32((void *)&xs); \
for (j = 0; j < 16; j ++) { \
ROUND_ONE_NEON; \
} \
vst1q_u32(&x0, mx0); \
vst1q_u32(&x4, mx4); \
vst1q_u32(&x8, mx8); \
vst1q_u32(&xc, mxc); \
vst1q_u32(&xg, mxg); \
vst1q_u32(&xk, mxk); \
vst1q_u32(&xo, mxo); \
vst1q_u32(&xs, mxs); \
} while (0)
//...
#if defined(__ARM_NEON__)
# define ROUND_ONE ROUND_ONE_NEON
# define SIXTEEN_ROUNDS SIXTEEN_ROUNDS_NEON
#else
# define ROUND_ONE ROUND_ONE_SLOW
# define SIXTEEN_ROUNDS SIXTEEN_ROUNDS_SLOW
#endif
前回と同様にcpuminer-multiのマクロに無理矢理はめ込んで実装しています。NEONを触るのは初めてで、非効率的な書き方になっているかもしれません。お気づきの点があれば教えてくださいませ。
(※)AMD A10-7600は昨日書いた通り1コア145kH/sですが、4コア並列だと145 x 4 = 580kH/sとはならず、少し効率が落ち490〜500kH/sほどになります。
コンパイラの本気はどこ行った
前回SSE化したときは1ラウンドの処理だけ書き換えれば事足りましたが、今回NEON化したときは16ラウンドのループも書き換える必要がありました。
何故かというとx64と違ってarmhfの場合、コンパイラがあまり良い結果を出力してくれないからです。gcc-7.2 x64の場合、
- load
- add
- xor
- store
このような処理をループさせても、生成されたバイナリの逆アセンブルを見ると、
- load
- ※
- add
- xor
- ※に戻る
- store
以上のようにload/storeの無駄を検知してループ「外」に追い出してくれました。しかしgcc-4.9 armhfの場合、ループ「内」にload/storeが残ってしまい、かなり遅くなります。
原因としてgccのバージョンが古い、アーキテクチャの最適化がこなれてない、NEONのIntrinsicsを使うと最適化が制限される、などいくつか考えられますが、今のところ分かりません。gcc-7にしたらコンパイラが賢くやってくれるようになれば一番楽ですけどね……。
コメント一覧
- コメントはありません。
この記事にコメントする
2017年11月30日
モナコインとCubeHash
先日(2017年11月24日の日記参照)CPUによるモナコインのマイニングcpuminer-multiについて調べました。先日の成果としては、
- CubeHashというハッシュ関数がとびきり時間が掛かっている
- cpuminer-multiは既に手動で最適化されている
- CubeHashを素朴に実装したら遅い
- 素朴な実装でもコンパイラの最適化でcpuminer-multiの実装と同等の速度が出る
CubeHashを適当にSSE化して遊んでいたところ、基本的には非常に遅く(改変前80kH/s、改変後30〜60kH/s)なりますが、突然100kH/sに速くなるポイントがありました。なお、我が家のマシンはAMD A10-7800/3.5GHzです。
コンパイラの本気
急激に速くなった理由はおそらくコンパイラです。
途中までしかSSE化していないはずなのに、逆アセンブラで見ると1ラウンドが全てベクタ演算命令で記述されていること、また、コンパイラの最適化レベルを変えずに(Ofast)、ベクタ最適化だけ無効にすると、速度が67kH/sに落ちることから、
- 私が中途半端にSSEを使った
- 変数間の依存性か何かが途切れた
- コンパイラが残りの部分を全部ベクタ化できると判断
- 1ラウンド全てSSE or AVX化された
このようなメカニズムだろうと思っています。
平たく言えばコンパイラが本気出していなかっただけですね。1ラウンドを全てベクタ演算化すると、なんと120kH/s も速度が出ました。
元のコードの1.5倍の速度を拝めるとは思ってもいませんでした。何でもやってみるものですね!
Intel Intrinsics
SSE化にはIntel Intrinsics(マニュアル)を使いました、というより、Intrinsicが無かったらSSE化をしようと思わないです。
Intrinsicはかなり強引ですけど、一応Cの関数として定義されており、人間が考えると面倒なこと(SSEレジスタ割り当て、退避など)は全てコンパイラがやってくれるため、大変便利です。
インラインアセンブラの一種とも言えますが、gccのインラインアセンブラほど苦痛はありません。SSE/AVXを使いたいだけならIntrinsicがおススメです。
手で頑張ってみよう
最初CubeHashのSTEP5(キューブの上面と下面の入れ替え操作)をシフトとORで計算していたのですが、コンパイラが出す命令を見ていたらshuffleという素敵な命令を使っていたので、そっちで書き直してみました。
コンパイラ任せでも良いのですが、せっかく途中まで書いたので、全部SSE化しました。BeforeとAfterはこんな感じです。
SSE2を使ったCubeHashの素朴な実装
#define SSE_ROTL(x, n) do { \
__m128i mw0, mw1; \
mw0 = _mm_slli_epi32((x), (n)); \
mw1 = _mm_srli_epi32((x), 32 - (n)); \
x = _mm_or_si128(mw0, mw1); \
} while (0);
#define SSE_SWP(a, b) do { \
__m128i mw; \
mw = b; \
b = a; \
a = mw; \
} while (0);
#define ROUND_ONE do { \
__m128i mx0, mx4, mx8, mxc; \
__m128i mxg, mxk, mxo, mxs; \
mx0 = _mm_load_si128((void *)&x0); \
mx4 = _mm_load_si128((void *)&x4); \
mx8 = _mm_load_si128((void *)&x8); \
mxc = _mm_load_si128((void *)&xc); \
mxg = _mm_load_si128((void *)&xg); \
mxk = _mm_load_si128((void *)&xk); \
mxo = _mm_load_si128((void *)&xo); \
mxs = _mm_load_si128((void *)&xs); \
/* STEP1 */ \
mxg = _mm_add_epi32(mx0, mxg); \
mxk = _mm_add_epi32(mx4, mxk); \
mxo = _mm_add_epi32(mx8, mxo); \
mxs = _mm_add_epi32(mxc, mxs); \
/* STEP2 */ \
SSE_ROTL(mx0, 7); \
SSE_ROTL(mx4, 7); \
SSE_ROTL(mx8, 7); \
SSE_ROTL(mxc, 7); \
/* STEP3 */ \
SSE_SWP(mx0, mx8); \
SSE_SWP(mx4, mxc); \
/* STEP4 */ \
mx0 = _mm_xor_si128(mx0, mxg); \
mx4 = _mm_xor_si128(mx4, mxk); \
mx8 = _mm_xor_si128(mx8, mxo); \
mxc = _mm_xor_si128(mxc, mxs); \
/* STEP5 */ \
mxg = _mm_shuffle_epi32(mxg, 0x4e); \
mxk = _mm_shuffle_epi32(mxk, 0x4e); \
mxo = _mm_shuffle_epi32(mxo, 0x4e); \
mxs = _mm_shuffle_epi32(mxs, 0x4e); \
/* STEP6 */ \
mxg = _mm_add_epi32(mx0, mxg); \
mxk = _mm_add_epi32(mx4, mxk); \
mxo = _mm_add_epi32(mx8, mxo); \
mxs = _mm_add_epi32(mxc, mxs); \
/* STEP7 */ \
SSE_ROTL(mx0, 11); \
SSE_ROTL(mx4, 11); \
SSE_ROTL(mx8, 11); \
SSE_ROTL(mxc, 11); \
/* STEP8 */ \
SSE_SWP(mx0, mx4); \
SSE_SWP(mx8, mxc); \
/* STEP9 */ \
mx0 = _mm_xor_si128(mx0, mxg); \
mx4 = _mm_xor_si128(mx4, mxk); \
mx8 = _mm_xor_si128(mx8, mxo); \
mxc = _mm_xor_si128(mxc, mxs); \
/* STEP10 */ \
mxg = _mm_shuffle_epi32(mxg, 0xb1); \
mxk = _mm_shuffle_epi32(mxk, 0xb1); \
mxo = _mm_shuffle_epi32(mxo, 0xb1); \
mxs = _mm_shuffle_epi32(mxs, 0xb1); \
_mm_store_si128((void *)&x0, mx0); \
_mm_store_si128((void *)&x4, mx4); \
_mm_store_si128((void *)&x8, mx8); \
_mm_store_si128((void *)&xc, mxc); \
_mm_store_si128((void *)&xg, mxg); \
_mm_store_si128((void *)&xk, mxk); \
_mm_store_si128((void *)&xo, mxo); \
_mm_store_si128((void *)&xs, mxs); \
} while (0)
前回と同様にcpuminer-multiのマクロにはめ込めるように実装しています。
実行例
$ ./cpuminer -a lyra2rev2 -t 1 --benchmark ** cpuminer-multi 1.3.3 by tpruvot@github ** BTC donation address: 1FhDPLPpw18X4srecguG3MxJYe4a1JsZnd (tpruvot) [2017-12-01 02:21:05] 1 miner threads started, using 'lyra2rev2' algorithm. [2017-12-01 02:21:06] CPU #0: 140.04 kH/s [2017-12-01 02:21:06] Total: 140.04 kH/s [2017-12-01 02:21:10] Total: 145.47 kH/s [2017-12-01 02:21:15] CPU #0: 145.32 kH/s [2017-12-01 02:21:15] Total: 145.32 kH/s
CubeHashの最終160ラウンドは一番のボトルネックだった個所だけあって、改善効果はかなり大きいですね。
コメント一覧
- AVXならこんな感じ?さん(2018/01/23 09:38)
/* STEP1 */ \
mxg = _mm256_add_epi32(mx0, mxg); \
mxo = _mm256_add_epi32(mx8, mxo); \
/* STEP2 */ \
AVX_ROTL(mx0, 7); \
AVX_ROTL(mx8, 7); \
/* STEP3 */ \
AVX_SWP(mx0, mx8); \
/* STEP4 */ \
mx0 = _mm256_xor_si256(mx0, mxg); \
mx8 = _mm256_xor_si256(mx8, mxo); \
/* STEP5 */ \
mxg = _mm256_permute4x64_epi64(mxg, 0xb1); \
mxo = _mm256_permute4x64_epi64(mxo, 0xb1); \
/* STEP6 */ \
mxg = _mm256_add_epi32(mx0, mxg); \
mxo = _mm256_add_epi32(mx8, mxo); \
/* STEP7 */ \
AVX_ROTL(mx0, 11); \
AVX_ROTL(mx8, 11); \
/* STEP8 */ \
mx0 = _mm256_permute4x64_epi64(mx0, 0x4e); \
mx8 = _mm256_permute4x64_epi64(mx8, 0x4e); \
/* STEP9 */ \
mx0 = _mm256_xor_si256(mx0, mxg); \
mx8 = _mm256_xor_si256(mx8, mxo); \
/* STEP10 */ \
mxg = _mm256_shuffle_epi32(mxg, 0xb1); \
mxo = _mm256_shuffle_epi32(mxo, 0xb1); \ - すずきさん(2018/01/24 14:40)
コメントありがとうございます。そのようになると思います。
私の実装は下記のような感じです。STEP5, 8 が多少違うくらいですね。
mxg = _mm256_add_epi32(mx0, mxg); \
mxo = _mm256_add_epi32(mx8, mxo); \
AVX_ROTL(mx0, 7); \
AVX_ROTL(mx8, 7); \
AVX_SWP(mx0, mx8); \
mx0 = _mm256_xor_si256(mx0, mxg); \
mx8 = _mm256_xor_si256(mx8, mxo); \
mxg = _mm256_shuffle_epi32(mxg, 0x4e); \
mxo = _mm256_shuffle_epi32(mxo, 0x4e); \
mxg = _mm256_add_epi32(mx0, mxg); \
mxo = _mm256_add_epi32(mx8, mxo); \
AVX_ROTL(mx0, 11); \
AVX_ROTL(mx8, 11); \
mx0 = _mm256_permute2x128_si256(mx0, mx0, 0x01); \
mx8 = _mm256_permute2x128_si256(mx8, mx8, 0x01); \
mx0 = _mm256_xor_si256(mx0, mxg); \
mx8 = _mm256_xor_si256(mx8, mxo); \
mxg = _mm256_shuffle_epi32(mxg, 0xb1); \
mxo = _mm256_shuffle_epi32(mxo, 0xb1);
残念ながら AMD A10 は AVX2 に対応していないので、SSE2 との速度が比較できませんが…。
この記事にコメントする
2017年11月26日
仮想通貨とマイニング
マイニングは仮想通貨の決済システムを支える大事な計算のようです。仮想通貨のシステム維持に協力してくれてありがとう、という意味を込めてマイニングした人にはボーナスが与えられているんですね。
私も最初マイニングという単語から、仮想通貨が地面から沸いてくるようなイメージを持っていましたが、決してそんなことはなくて、マイニングには高いコスト、つまり、計算するハードの初期投資と維持する電気代が掛かっています。
日本は電気代が高くて、維持費と得られる仮想通貨の量(を日本円換算した額)が、割に合わないです。
もしモナコインを使ってみたいだけなら、日本円と仮想通貨を交換してくれるところから得るのが一番楽だと思います。仮想通貨を手に入れる手段として、マイニングはあまり効率が良いとは思いません。無駄に時間と金が掛かるだけです。もちろんマイニング自体に興味がある人は別ですよ。
先日私が調べていたCPUマイニング(2017年11月24日の日記参照)ではかなり「ハッシュ数/電力」の効率が悪く、マイニングの手法としては、ほぼ意味がありません。
現在Lyra2REv2はGPUマイニングが主流のようです。私もccminerというCUDAを使ったマイナーを試しています。ローエンドGeForce GT 1030 1枚ですら6MH/sで、CPUの100倍くらいの速度です。すごいね、GPUって。
それでもマイニングするには貧弱な計算力なので、GPU数枚程度ならマイニングプールを使うことになると思います。
メモ: 技術系の話はFacebookから転記しておくことにした。
コメント一覧
- コメントはありません。
この記事にコメントする
2017年11月24日
モナコイン
仮想通貨の勉強がてら、モナコイン(以外の仮想通貨にも対応してますが)のマイナーcpuminer-multiを見ていました。かなり最適化されていて、迂闊にSSEを使うと逆に遅くなるほどです。面白いです。
モナコインのハッシュアルゴリズムはLyra2REv2という名前の256ビットハッシュ関数で、複数のハッシュ関数の組み合わせでできています。
- blake
- keccak
- cubehash
- LYRA2
- skein
- cubehash(2回目)
- bmw
上から順に実行されます。先頭のblakeへの入力は80バイトで、出力は32バイト。1つ前のハッシュ関数の出力が、2番目以降のハッシュ関数の入力となります。LYRA2だけパラメータが2つ(saltとpassword)必要ですが、どちらも同じ値を指定していました。
Lyra2REv2をCPUで演算する場合CubeHashに一番時間が掛かります。2回実行されることを差し引いて考えても遅いです。見ていると最終ラウンドが160回という設定になっていて、これが異常に遅いみたいです。
実装(=cpuminer-multiの最適化された実装)を見ると、このハッシュ関数は4ワードと別の4ワードをペアにして演算をします。ワーク領域は32ワードありますので、同じ演算が4回実行されます。いかにもSSEに向いていそうな処理ですが、4ワードの組み合わせ方が変わるので、SSEレジスタにうまくパッキングできません。
- (EVENラウンド)
- 加算★
- 左ローテート
- XOR★
- 2ワードずらして加算
- 左ローテート
- 2ワードずらしてXOR
- (ODDラウンド)
- 逆順で加算
- 左ローテート
- 逆順でXOR
- 逆順2ワードずらして加算
- 左ローテート
- 逆順2ワードずらしてXOR
試しに★の部分だけ、単純にSSEを使ったら、余計遅くなりました。切ない。どうもSSEレジスタからのロード/ストアで引っかかって遅くなっているようです。しかしSSEには左ローテート演算がないため、左ローテートの前に必ずストアしなければなりません。
EVEN + ODDのラウンドが8回繰り返されますが、安易にunrollingしても(※)やはり遅くなります。unrollingした後のマシン語を見ると嫌になるくらい長いので、命令キャッシュのヒット率が落ちてるのかな?
うーん、難しいです……。
(※)私が何かしたわけではなくcpuminer-multiにはunrollingするコンパイルオプションが用意されていて、それを使ってみただけです。CubeHash以外のハッシュ関数もunrollingするかしないかを選べます。素敵な作りです。
CubeHash
そもそもCubeHashって何なのか全く知らないので調べてみました。Wikipediaの解説(リンク)がとても親切です。CubeHashはNISTのハッシュ関数コンペに応募されたものなのだとか。次のSHAなんちゃらに採用されるかもしれないですね。
CubeHashにはパラメータがあり、パラメータが違うと全く違うハッシュ関数になります。Lyra2REv2で使用しているのはどれ、という情報が見当たらなかったのですが、cpuminer-multiの実装(初期ラウンドは不明ですが、1周16ラウンド、ブロックサイズ32ビット、最終160ラウンド、ハッシュ長256ビット)から推測するにCubeHash160+16/32+160-256じゃないか?と思われます。長い名前だなあ……。
キューブは4個あって、i, jの2次元で指定されます。i, jは0か1の値しかとりません。
キューブは8個のブロックから構成されk, l, mの3次元で指定されます。k, l, mも0か1の値しか取りません。
ブロックは32ビットです…、というよりLyra2REv2のCubeHashの場合は32ビット、と言った方が正しいですね。
従って、全体で4 * 8 = 32個のブロックが存在します。Wikipediaの図ではi, j, k, l, mという5次元のアドレスで表現していますが、計算の際はi, j, k, l, mをくっつけて2進数だと思って数値に変換します。
例えば、右下のキューブ(i = 1, j = 0)、右上の手前側ブロック(k = 1, l = 1, m = 0)だったら、ijklm = 10110 = 22になりま…、はい?わかりづらい?
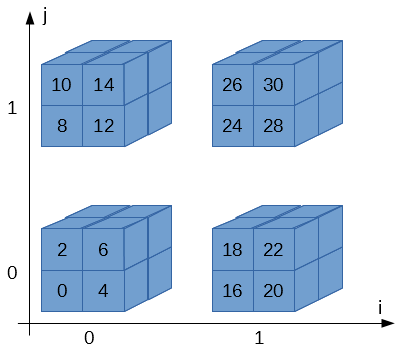
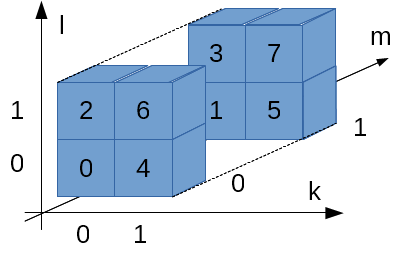
これでわかりやすい?
CubeHashの素朴な実装
Wikipediaに載っている実装をそのまま実装すれば良いです。と言われてやる人は居ませんから、自分でやってみます。
アルゴリズムだけ実装しても、結果を確かめる術がないのでcpuminer-multiに組み込める形で実装します。sha3/sph_cubehash.cにSIXTEEN_ROUNDSというマクロがあって、CubeHashの1周(16ラウンド)に相当しています。このマクロを改造して自作の実装を差し込みます。
CubeHashの素朴な実装、準備編
#if 1 //今から作る実装を無理やり有効にする
#define SIXTEEN_ROUNDS do { \
int j; \
for (j = 0; j < 16; j ++) { \
ROUND_ONE; \
} \
} while (0)
#elif SPH_CUBEHASH_UNROLL == 2 //#ifを #elifに変えてしまう(SPH_CUBEHASH_UNROLLオプションを無視)
#define SIXTEEN_ROUNDS do { \
int j; \
for (j = 0; j < 8; j ++) { \
ROUND_EVEN; \
ROUND_ODD; \
} \
} while (0)
次にラウンドの処理を書きます。Wikipediaを見ながら10個の手順をそのまま書きます。
CubeHashの素朴な実装
void sw(uint32_t *a, uint32_t *b)
{
uint32_t tmp = *b;
*b = *a;
*a = tmp;
}
#define ROUND_ONE do { \
int i; \
uint32_t *b = (sc)->state; \
/* STEP 1, 2 */ \
for (i = 0; i < 16; i++) { \
b[i + 16] += b[i]; \
b[i] = ROTL32(b[i], 7); \
} \
/* STEP 3 */ \
for (i = 0; i < 8; i++) { \
sw(&b[i], &b[i + 8]); \
} \
/* STEP 4 */ \
for (i = 0; i < 16; i++) \
b[i] ^= b[i + 16]; \
/* STEP 5 */ \
for (i = 0; i < 4; i++) { \
sw(&b[16 + i * 4], &b[18 + i * 4]); \
sw(&b[17 + i * 4], &b[19 + i * 4]); \
} \
/* STEP 6, 7 */ \
for (i = 0; i < 16; i++) { \
b[i + 16] += b[i]; \
b[i] = ROTL32(b[i], 11); \
} \
/* STEP 8 */ \
for (i = 0; i < 4; i++) { \
sw(&b[0 + i], &b[4 + i]); \
sw(&b[8 + i], &b[12 + i]); \
} \
/* STEP 9 */ \
for (i = 0; i < 16; i++) \
b[i] ^= b[i + 16]; \
/* STEP 10 */ \
for (i = 0; i < 4; i++) { \
sw(&b[16 + i * 4], &b[17 + i * 4]); \
sw(&b[18 + i * 4], &b[19 + i * 4]); \
} \
} while (0)
コンパイルして動けばOKです。
実行例
$ ./cpuminer -a lyra2rev2 -t 1 --benchmark ** cpuminer-multi 1.3.3 by tpruvot@github ** BTC donation address: 1FhDPLPpw18X4srecguG3MxJYe4a1JsZnd (tpruvot) [2017-11-24 20:25:06] 1 miner threads started, using 'lyra2rev2' algorithm. [2017-11-24 20:25:07] CPU #0: 68.54 kH/s [2017-11-24 20:25:07] Total: 68.54 kH/s [2017-11-24 20:25:11] Total: 80.77 kH/s [2017-11-24 20:25:16] CPU #0: 80.76 kH/s [2017-11-24 20:25:16] Total: 80.76 kH/s
もし高速化に挑むのであれば、ハッシュ関数の出力する結果が合っているかどうかも見た方が良いです。基本的には、変更前の結果と比べて同じかどうかをチェックします。まあ、マイニングプールに繋いでみてacceptが返ることでも確かめられますけど、マイニングプールに迷惑なのでほどほどにね……。
コンパイラの本気を見よ
この素朴な実装はとても遅いです。我が家のマシン(AMD A10-7800/3.5GHz)では、最適化レベルが -O2でも33kH/s程度しか出ません。cpuminer-multiの元々の実装(unrolling = 2)は80〜81kH/sくらいなので、天と地ほどの差があります。
元のcpuminer-multiの実装が速い理由は、ラウンドのswap処理を手動で解決し、2ラウンド分をunrollingしているからだと思われます。swapを手動展開するところで、記号の意味が訳わからなくなってしまうため、読むのはだいぶキツいものがあります。
ところがそこまでしなくても、実は -Ofast -march=nativeで最適化を掛けると79〜80kH/s程度と、かなり近い速度が出せてしまいます。出力されたコードはSSEによるベクタ化や命令並べ替えの多発で、人間には理解不能な感じになっちゃってますが、まーとにかく速いです。コンパイラの本気を見た気がしますね。
コメント一覧
- すずきさん(2017/11/26 17:09)
SHA-3 はもう決定していて、keccak が採用されたそうです。
Wikipedia をちゃんと読んだら 「CubeHash は 2回戦までは行ったが、最終選考の 5つに残れなかった」と書いてありました。
この記事にコメントする
| < | 2017 | > | ||||
| << | < | 12 | > | >> | ||
| 日 | 月 | 火 | 水 | 木 | 金 | 土 |
| - | - | - | - | - | 1 | 2 |
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 31 | - | - | - | - | - | - |
こんてんつ
wiki Linux JM Java API過去の日記
2002年 2003年 2004年 2005年 2006年 2007年 2008年 2009年 2010年 2011年 2012年 2013年 2014年 2015年 2016年 2017年 2018年 2019年 2020年 2021年 2022年 2023年 2024年 過去日記についてその他の情報
アクセス統計 サーバ一覧 サイトの情報
合計:
本日:

管理者: Katsuhiro Suzuki(katsuhiro( a t )katsuster.net)
This is Simple Diary 1.0
Copyright(C) Katsuhiro Suzuki 2006-2023.
Powered by PHP 8.2.15.
using GD bundled (2.1.0 compatible)(png support.)